[TOC]
单元变量线性回归
Model
Cost Function:平方误差函数
MSE:
求解方法
- 批量梯度下降(batch gradient descent)

多元变量线性回归
Model
引入
矩阵的表达方式
Cost Function
MSE:
求解方法
批量梯度下降
Repeat {
(simultaneously update all )
}
求导后得到:
Repeat {
(simultaneously update all )
}
同步更新
Normal Equation
优点:直接求出最优解
缺点:
- 要求
可逆,这个一般问题不大,可以用伪逆,或者加入正则项后保证了可逆 - 最主要缺点:不适用大型数据集,矩阵X太大(或者说样本太多)求逆矩阵太慢,不可能
梯度下降与正规方程的比较:
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 |
不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量 |
需要计算 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数$\theta $的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
实践
- 特征缩放:我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。最简单的方法是令:
,其中 是平均值, 是标准差。
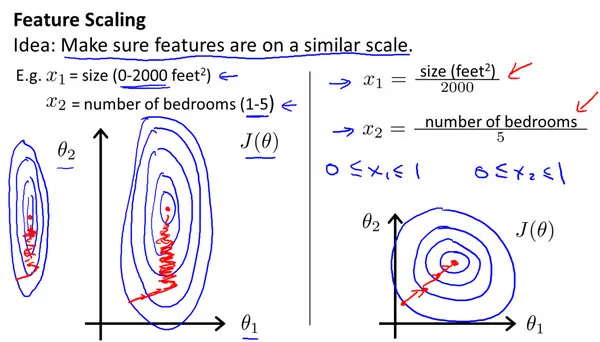
- 选择学习速率并绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛,可以尝试的速率
。如果学习率a过小,则达到收敛所需的迭代次数会非常高;如果学习率a过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛
变种:多项式回归
如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要
多项式回归这个指的是二次模型或者三次模型等
- 二次:
- 三次:
一般情况下,我们可以对进行处理,
逻辑回归
模型
需要一个值域0-1之间的函数来表示
逻辑回归+sigmoid函数
逻辑回归模型的假设是:
代表特征向量 代表逻辑函数(logistic function)是一个常用的逻辑函数为S形函数(Sigmoid function),公式为:
又当
时,预测 时,预测

上述模型的表示可以理解为决策边界:
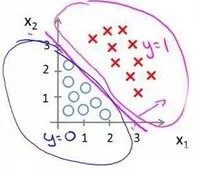
同样地,如果把
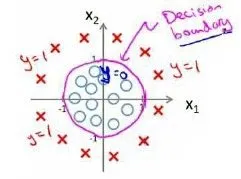
Cost Function
是否继续使用线性回归的MSE?:不行,
带入 后,代价函数J函数非凸,有许多局部最小值,这将影响梯度下降算法寻找全局最小值
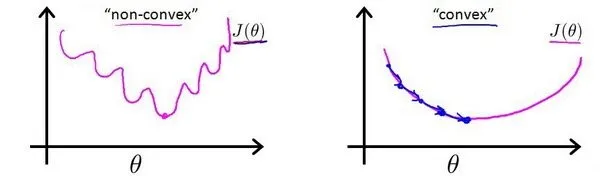
重新定义逻辑回归的代价函数为:
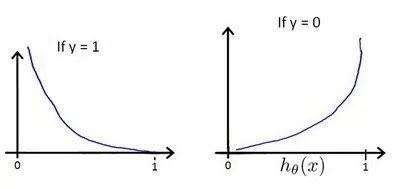
最终的
为何使用log作为代价函数
- 首先就像前面说的可以证明现在的
是一个凸性分析(凸性分析) - 更深层次的推导,是通过极大似然估计,推导出likelihood-based的损失函数,他又是广义线性回归中指数分布族的特例(之前的多元线性回归也是),可以参考吴恩达斯坦福课程第四课
求解方法
使用梯度下降法
Repeat {
(simultaneously update all )
}
求导后得到:
Repeat {
(simultaneously update all )
}
注意:
- 虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里的
与线性回归中不同,所以实际上是不一样的。 - 另外,在运行梯度下降算法之前,进行特征缩放依旧是非常必要的
其他求代价函数极值的高级方法
共轭梯度(Conjugate Gradient),局部优化法(Broyden fletcher goldfarb shann,BFGS)和有限内存局部优化法(LBFGS)
优点:
- 不用选择学习速率:他们确实有一个智能的内部循环,称为线性搜索(line search)算法,它可以自动尝试不同的学习速率
,并自动选择一个好的学习速率 , - 更快求到极值
实现方法:fminunc是 matlab和octave 中都带的一个最小值优化函数,使用时我们需要提供一个自定义函数,它返回一个求代价函数和对每个参数的求导的元组,然后就可以自动执行优化过程了(不需要你选择学习速率)
示例如下(有两个参数theta1 theta2)
function [jVal, gradient]=costFunction(theta)
jVal=(theta(1)-5)^2+(theta(2)-5)^2;
gradient=zeros(2,1);
gradient(1)=2*(theta(1)-5);
gradient(2)=2*(theta(2)-5);
end
options=optimset('GradObj','on','MaxIter',100);
initialTheta=zeros(2,1);
[optTheta, functionVal, exitFlag]=fminunc(@costFunction, initialTheta, options);
总结:所以当我有一个很大的机器学习问题时,我会选择这些高级算法,而不是梯度下降。
多元分类问题
问题如下
解决:"一对余"方法
我们将多个类中的一个类标记为正向类(
模型总结为:
预测时即为找出概率最大的分类:
正则化--L2正则
使用复杂模型时会遇到过拟合(over-fitting)的问题。
例如,使用多项式结合线性回归/逻辑回归时,太多的高次项导致过拟合,即在训练集表现良好,但在预测新数据时效果不行
回归问题如下:

分类问题如下:
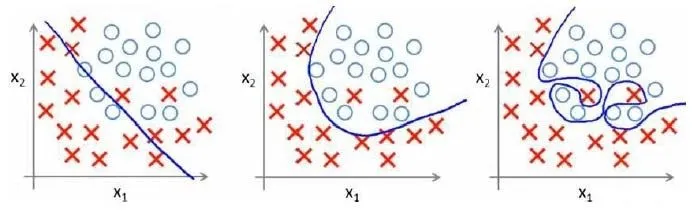
可能的解决办法:
- 丢弃一些特征
- 手工选择保留哪些特征
- 使用一些模型选择的算法来帮忙(例如PCA)
- 正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
Cost function
可以发现高次项导致了过拟合的产生,因此我们需要惩罚高次项。例如对于假设函数
假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度。
其中,$\lambda $又称为正则化参数(Regularization Parameter)。
注:根据惯例,我们不对
进行惩罚
效果如下:
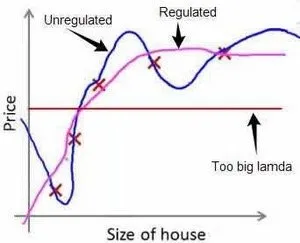
正则化线性回归
- Cost Function
- 求解方法--梯度下降:注意
没有正则
{
} - 求解方法-正规方程
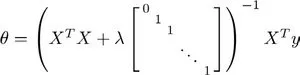
正则化逻辑回归
- Cost Function
注意:对比正则项前的常数项,与之前线性回归保持一致,逻辑回归前一项目的1/2没有了是被log函数整体替换了,参考前面逻辑回归一节 - 求解--梯度下降:形式与回归一致
{
}
注意:
- 虽然正则化的逻辑回归中的梯度下降和正则化的线性回归中的表达式看起来一样,但由于两者的
不同所以还是有很大差别。 不参与其中的任何一个正则化。
神经网络
基本的想法:一种表示能力极强的非线性模型
问题:使用线性回归+多项式特征的模型有什么问题?
答:特征组合出现了爆炸,例如大于100个变量,我们希望用这100个特征来构建一个非线性的多项式模型,结果将是数量非常惊人的特征组合,即便我们只采用两两特征的组合
因此,观察神经网络的结构,可以把每一层当做是对特征的某种组合:如下图我们可以把
这就是神经网络相比于逻辑回归和线性回归的优势。
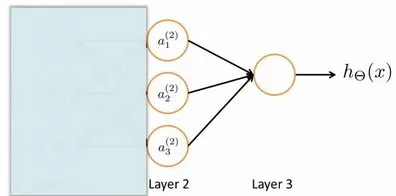
模型
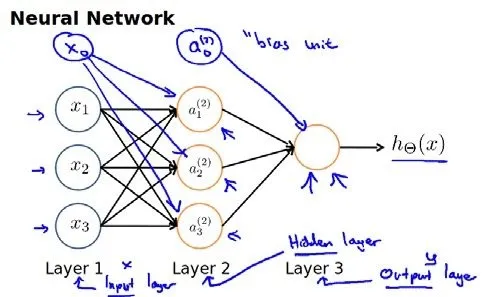
上图中加入了偏置单元,注意偏置单元只作为输入,没有作为输出。
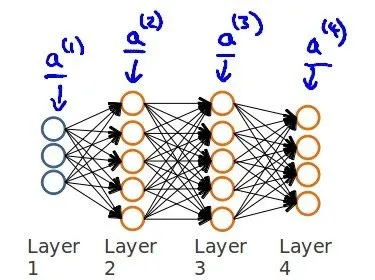
下面引入一些标记法来帮助描述模型:
对于上图所示的模型,激活单元和输出分别表达为:
矩阵表示为:
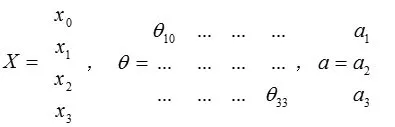
即:
FORWARD PROPAGATION
每一层的计算方法如下
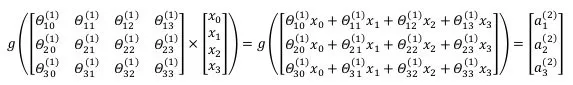
注意:
理解模型特征与表现能力
大部分资料都是从逻辑运算符上来理解的
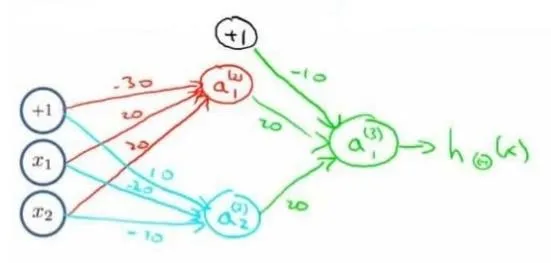
线性模型可以表示AND,OR运算,可以用一个神经元来模拟
但是对于异或XOR运算,没法用一个线性模型表达,因此使用两个多个神经元组合。类似下图
多分类问题
上面的模型的输出层只有一个神经元。如果多分类,如4分类可以输出层4个神经元分别用来表示4类
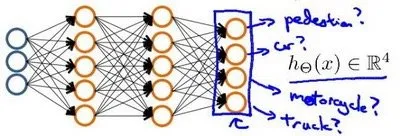
其中输出层的值可能如下:
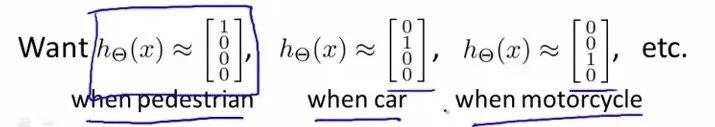
cost function
我们定义神经网络如下:
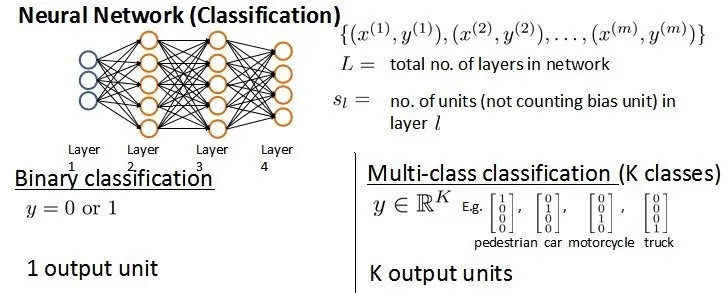
对比逻辑回归的Cost Function,这里有k个输出:
注意:正则化的那一项只是排除了每一层
求解问题:反向传播
对上面的Cost Function求最小值也是使用梯度下降。问题编程了如何就上面这个复杂J函数的梯度,也就是求所有参数theta的偏导数:
分析下面的反向传播过程
以一次过程过程(一个样本)为例:
- 从Layer4->Layer3
其中 表示误差error - 利用这个误差值来计算前一层的误差:
,其中 是 形函数的导数, 。而 则是权重导致的误差的和
- Layer3->Layer2:
- 有了所有的误差的表达式后,便可以计算代价函数的偏导数了(不含正则):
:why??????
最后异步推导没看懂
下面是m次过程(m个样本)累计后求均值(1/m)更新一次偏导数

在求出了
$ D_{ij}^{(l)} :=\frac{1}{m}\Delta_{ij}^{(l)}+\lambda\Theta_{ij}^{(l)}$
$ D_{ij}^{(l)} :=\frac{1}{m}\Delta_{ij}^{(l)}$
梯度检验
我们知道上面计算梯度的过程(偏导)非常复杂,为了确保正确,我们需要一直检验计算结果的方法。这里使用了逼近法求偏导的近似方法,叫做梯度的数值检验(Numerical Gradient Checking)方法:
对于某个特定的
当
按照上面的方法计算出所有的偏导,与上面反向传播的结果进行对比验证。
随机初始化参数
可以看到上面的模型中有参数
通常初始参数为正负ε之间的随机值
总结
构造模型结构:
- 选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。
- 第一层的单元数即我们训练集的特征数量。
- 最后一层的单元数是我们训练集的结果的类的数量。
- 我们真正要决定的是隐藏层的层数和每个中间层的单元数:如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。
训练神经网络:
- 参数的随机初始化
- 利用正向传播方法计算所有的
- 编写计算代价函数
的代码 - 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数
机器学习模型、系统的评估与分析
机器学习中一个最重要的问题就是,你训练完一个模型,下面该怎么办?他的效果怎么样,如果不好,怎么开始优化?什么的优化方向是正确的?能提升多少性能?
只有对这些问题做到心中有数,才能开发出好的模型
当我们运用训练好了的模型来预测未知数据的时候发现有较大的误差,我们下一步可以做什么?
- 获得更多的训练样本——通常是有效的,但代价较大,下面的方法也可能有效,可考虑先采用下面的几种方法。
- 尝试减少特征的数量
- 尝试获得更多的特征
- 尝试增加多项式特征
- 尝试减少正则化程度
- 尝试增加正则化程度
不应该随机选择上面的某种方法来改进我们的算法!!!
评估模型
- 为了评估没有见过的样本,我们需要测试集
- 为了模型选择又不污染测试集,我们需要交叉验证集合
- 使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集
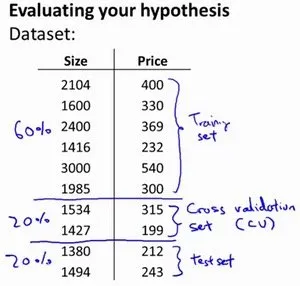
评估指标:
- 回归问题:在测试集上计算代价函数,即J函数 (不包括正则项),
- 分类问题:在测试集上计算误分类的比率,也可以用J函数
择模型选择的方法为:
- 使用训练集训练出10个模型
- 用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
- 选取代价函数值最小的模型
- 用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)
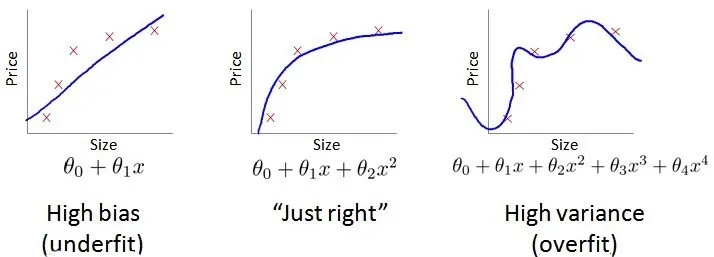
模型诊断:偏差和方差
算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。
下面的图就可以理解偏差方差:
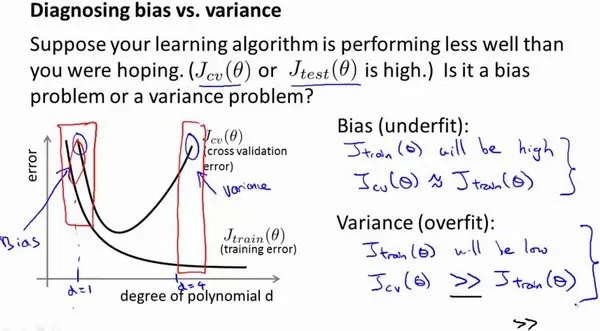
下面讲解如何了解当前是偏差还是方差的问题:
- 如何判断:将训练集代价函数
和交叉验证集的代价函数 误差与多项式的次数绘制在同一张图表上来帮助分析(注意横轴是模型复杂度,从小到大): - 训练集误差和交叉验证集误差近似时:偏差/欠拟合
- 交叉验证集误差远大于训练集误差时:方差/过拟合
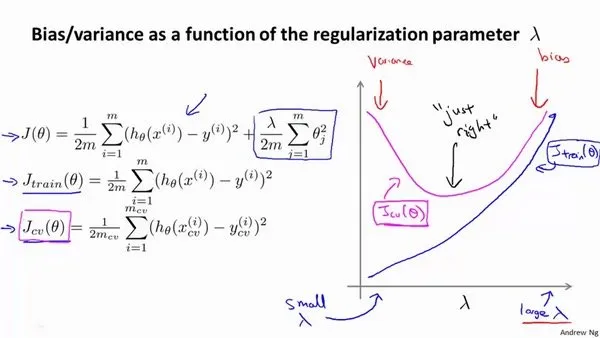
- 当使用正则化来代控制模型复杂度时,如何选择,绘制
与 图(注意横轴是 ,越大,模型复杂度月低,与上图相反) - 当
较小时,训练集误差较小(过拟合)而交叉验证集误差较大 - 随着
的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加
- 当
- 另一种判断方法是使用学习曲线(Learning Curves),他是一种快速的合理性检验方法(sanity check)。他也是绘制绘制
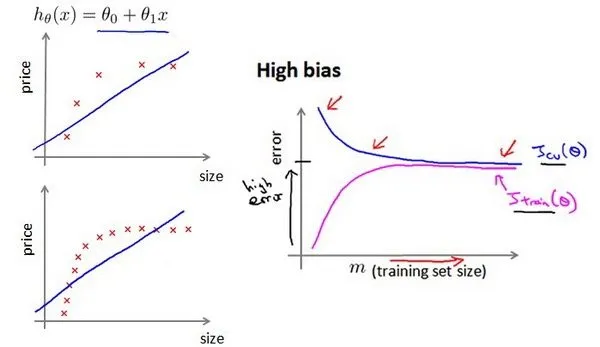
与 图,但是横轴是数据训练集大小m。思想是:当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据 - 识别高偏差/欠拟合:作为例子,我们尝试用一条直线来适应下面的数据,可以看出,无论训练集有多么大,误差都不会有太大改观(竖轴值都很大,且两者接近),此时再收集样本没什么用。
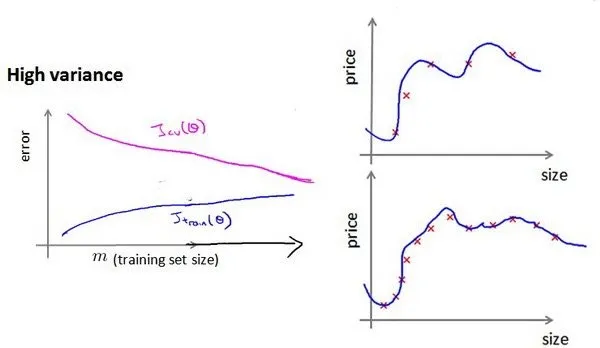
- 识别高方差/过拟合:假设我们使用一个非常高次的多项式模型,并且正则化非常小,可以看出,当交叉验证集误差远大于训练集误差时(竖轴值都小,前两者分开),往训练集增加更多数据可以提高模型的效果
- 识别高偏差/欠拟合:作为例子,我们尝试用一条直线来适应下面的数据,可以看出,无论训练集有多么大,误差都不会有太大改观(竖轴值都很大,且两者接近),此时再收集样本没什么用。
应对偏差方差
下面这些措施应对了偏差方差不同的情况,不要误入歧途:
- 获得更多的训练样本——解决高方差
- 尝试减少特征的数量——解决高方差
- 尝试获得更多的特征——解决高偏差
- 尝试增加多项式特征——解决高偏差
- 尝试减少正则化程度λ——解决高偏差
- 尝试增加正则化程度λ——解决高方差
一个demo:如何优化神经网络:
- 使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据,通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好
- 对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络
- 选择交叉验证集代价最小的神经网络
误差分析:以判别垃圾邮件为例机器学习系统设计
从头开始构建机器学习系统的方法:
- 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
- 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
- 进行误差分析(强烈推荐在交叉验证集上进行):
- 通过一个量化的数值评估,你可以看看这个数字,误差是变大还是变小了。
- 人工检查交叉验证集中我们算法中产生预测误差的样本,看看这些样本是否有某种系统化的趋势
我总是推荐你实现一个较为简单快速、即便不是那么完美的算法。然后通过误差分析,来看看他犯了什么错,来决定优化的方式,不断迭代系统。
误差分析的方法:选择一个好的误差度量值十分重要--类偏斜的误差度量
| 预测值 | |||
|---|---|---|---|
| Positive | Negtive | ||
| 实际值 | Positive | TP | FN |
| Negtive | FP | TN |
- 指标
- 查准率 TP/(TP+FP)
- 查全率 TP/(TP+FN)
- trade-off: 一种方法是计算F1 值(F1 Score),
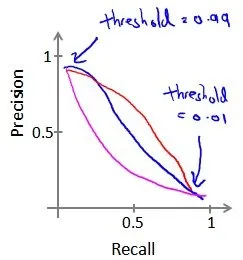
机器学习的数据问题:什么时候需要大数据(样本)
在一定条件下,如模型有大量的参数(这种情况下往往欠拟合)。得到大量的数据并在某种类型的学习算法中进行训练,可以是一种有效的方法来获得一个具有良好性能的学习算法
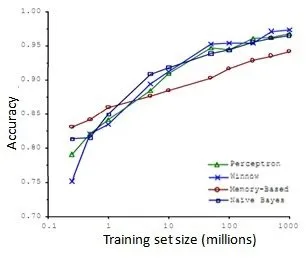
有人做了实验,即使模型(算法)不行,给大量的数据得到的结果会比一个好的算法+少量数据的效果好或者差不多:
从偏差方差的角度思考这个问题:我们希望有一个低偏差地方差的最终模型,因此可以:
- 偏差问题,我么将通过确保有一个具有很多参数的学习算法来解决
- 方差问题,我们通过大量的数据集来解决
两者结合,我们最终可以得到一个低误差和低方差的学习算法。
一个判断大数据是否能有效的方法:首先,一个人类专家看到了特征值
,能很有信心的预测出 值吗?因为这可以证明 $ y$ 可以根据特征值 被准确地预测出来。其次,我们实际上能得到一组庞大的训练集,并且在这个训练集中训练一个有很多参数的学习算法吗?如果你不能做到这两者,那么更多时候,你会得到一个性能很好的学习算法。
其他:上限分析
SVM与核函数
线性SVM与核函数SVM
假设函数
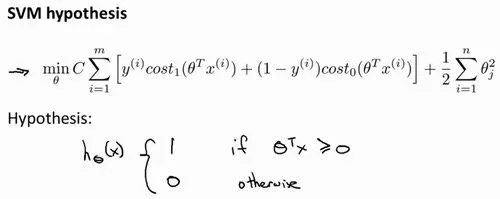
理解:从逻辑回归演变而来
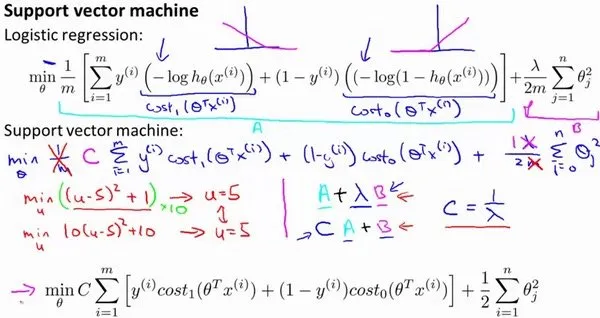
注意点:
- 上述C可以理解为正则参数的导数,
,因此C越小标志 越大,相当于增加了正则参数,使得模型泛化性增强,减少过拟合。 - 也可以这么理解C,在SVM的推导中,我们假设C是一个巨大的值,这种情况下意味着,必须是严格的间隔,不能容忍任何的边界划分错误,对异常值非常敏感,相当于过拟合了
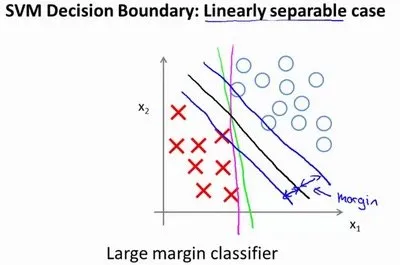
理解:为什么最小化上述函数就是代表最大间隔
- 当我们把
设置成了非常大的常数,我们将会很希望找到一个使第一项为0的最优解。因此,如果 是等于1,那么需要 , 如果 是等于0,那么需要 。这两个约束条件总结如下:

- 决策边界的效果如下,黑色的线优于绿色,他具有最大的间隔:
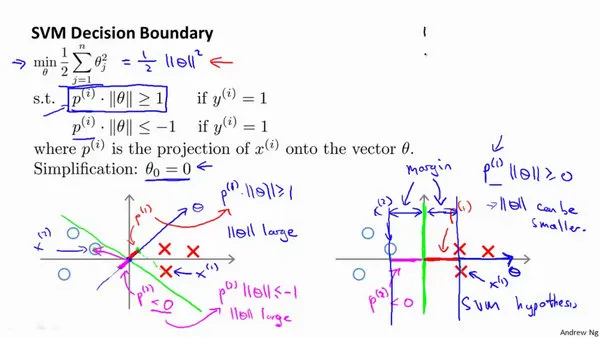
- 理解为何上述约束会生成黑色的线
- 把
看做两个向量的内积。为了使得 的同时最小化 ,因此 到 的投影必须尽量的大。(数学:向量的内机是一个数字,等于一个向量投影到另一的长度*另一个向量的长度/范数) - 下图中左边的投影(红色)比较小(p小),为了>=1则
则比较大,对比右图,会发现他的 比较小,对应的图中间隔比较大
- 把
核函数
上面的方法叫做线性SVM,分割的边界是直线,对于非线性的情况分割为曲线。
我们的模型可能是
思路:
- 在逻辑回归中:
我们可以用一系列的新的特征来替换模型中的每一项。例如令:
...得到。 - 然而,除了对原有的特征进行组合以外,有没有更好的方法来构造
? - 我们可以利用核函数来计算出新的特征。使用核函数把特征映射到更高维度,对于m个样本n个特征的数据集(
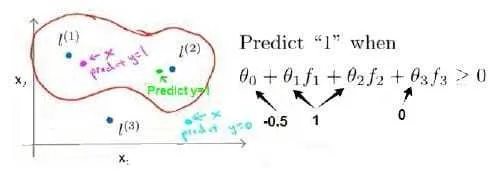
m*n个特征),我们对每个样本我们构造m个新特性(与样本数一样多!!即m*m个特征),然后在高维中使用线性svm来进行分类 - 映射的方法:对每个样本计算m个新特征:
,分别计算 。这里的 是样本集合中的一个其他样本,叫做地标, 刻画了与 的相似距离。这里的similarity就是核函数,这个叫高斯核

思考两个问题
- 为什么这种映射是可行的?感性的理解一下,样本空间如下,当样本处于洋红色的点位置处,因为其离
更近,但是离 和 较远,因此 接近1,而 , 接近0。因此 ,因此预测 。同理可以求出,对于离 较近的绿色点,也预测 ,但是对于蓝绿色的点,因为其离三个地标都较远,预测 。
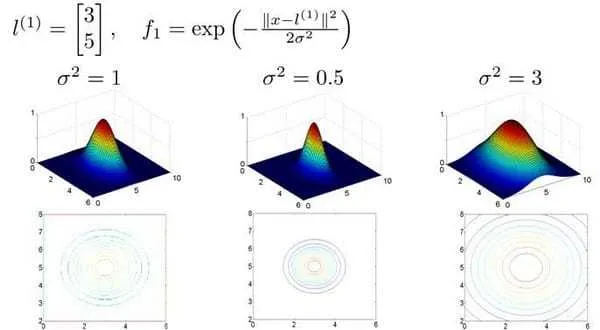
- 高斯核的作用?高斯核的图像如下,可以发现:
只有当与 重合时 才具有最大值。随着 的改变 值改变的速率受到 的控制。可以发当 比较小时,图像波动大,样本对距离非常敏感,结果是虽然模型偏差很低,但是方差较大(过拟合)
总结
下面是一些普遍使用的准则:
(1)如果相较于
(2)如果
(3)如果
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值
无监督学习-聚类
作用:找到数据中的结构或者模式
应用:
- 社交网络分析
- 数据中心优化
k均值算法
k个中心点,m个样本数据
Repeat {
for i = 1 to m
c(i) := index (form 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk := average (mean) of points assigned to cluster k
}
K均值的代价函数
其中
我们的的优化目标便是找出使得代价函数最小的
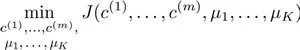
对照上面的算法:第一个循环是用于减小
随机初始化初始的中心点
方法:通常需要多次运行K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果
适用范围:K的数量小时比较有效,多的时候作用不大(K<10)
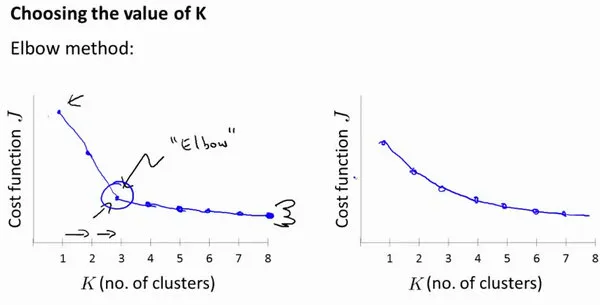
选择聚类族数目K
方法:肘部法则
就是实验法,选择代价函数下降最多的地方作为族数目:
无监督学习--降维问题-PCA
目的:
- 压缩存储,减少空间,加速运算---去除冗余特征,如不同单位km,cm的距离
- 数据可视化:把大于3维的特征降到3维,方便展示---问题:新的3维特性的含义很难理解
PCA
主成分分析问题的描述:
问题:将
目标:最小化的是投射误差(Projected Error),下图中把二维降维到一维时,点到线的距离就是投射误差
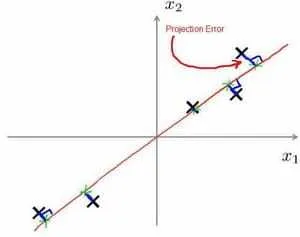
对比线性回归目标不同,方法相似,线性回归目标是预测,这里没有.
投射的方向不同,如下所示,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)
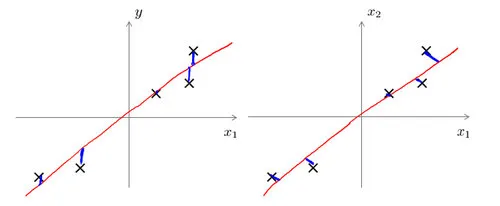
优点:PCA技术的一个很大的优点是,它是完全无参数限制的。
PCA算法过程
- 第一步是均值归一化。我们需要计算出所有特征的均值,然后令
。如果特征是在不同的数量级上,我们还需要将其除以标准差 。 - 第二步是计算协方差矩阵(covariance matrix)
:
- 第三步是计算协方差矩阵
的特征向量(eigenvectors):在Octave中用svd方法

- 如果我们希望将数据从
维降至 维,我们只需要从 中选取前 个向量,获得一个 维度的矩阵,我们用 表示,然后通过如下计算获得要求的新特征向量 :$$z^{(i)}=U^{T}_{reduce}*x^{(i)}$$
k的选择,降到多少维度?
方法一:
主要成分分析是减少投射的平均均方误差:
训练集的方差为:
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的
如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。
我们可以先令
方法二(推荐):
当我们在Octave中调用“svd”函数的时候,我们获得三个参数:[U, S, V] = svd(sigma)。
也就是:$$\frac {\Sigma^{k}{i=1}s{ii}}{\Sigma^{n}{i=1}s{ii}}\geq0.99$$
在压缩过数据后,我们可以采用如下方法来近似地获得原有的特征:$$x^{\left( i\right) }{approx}=Uz^{(i)}$$
具体操作可以是
- 对S的对角线进行排序
- 选择前k个大的值
- 使得2中的占总对角线和的值的比例>99%
重建的压缩表示
还原回去:略。。。
结合算法的使用过程
假使我们正在针对一张 100×100像素的图片进行某个计算机视觉的机器学习,即总共有10000 个特征。
- 第一步是运用主要成分分析将数据压缩至1000个特征
- 然后对训练集运行学习算法(用压缩后的数据)
- 在预测时,采用之前学习而来的
将输入的特征 转换成特征向量 ,然后再进行预测
注:如果我们有交叉验证集合测试集,也采用对训练集学习而来的
。
误区
- 不要把PCA用来解决过拟合,而是应该用正则来解决
- 不要一开始就用PCA,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析
无监督学习--异常检测(仅在验证与测试混合了部分监督学习)
目的:给定一组没有标签的数据,开发一个模型p(x),来判断新数据X是否异常。下图中圈出了正常的数据的范围,外部就是异常数据。
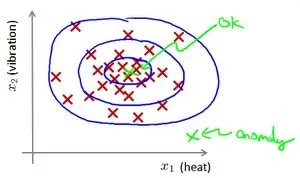
模型定义:
如在欺诈检测中,当
基本假设与算法
假设:特征变量
算法:
- 对于给定的数据集
,我们要针对每一个特征计算 和 的估计值。基于此计算出n个高斯分布
- 然后计算n个高斯分布的乘积(这里隐含假设各个特征相互独立)
- 当
时,为异常。
一个有两个特征的模型例子如下:圈定的范围由于不同的方差形成了一个水平的椭圆
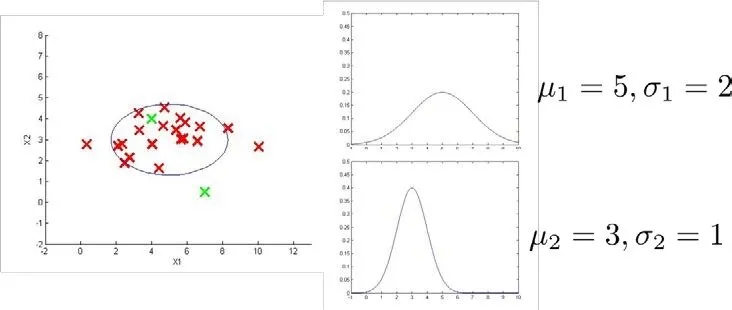
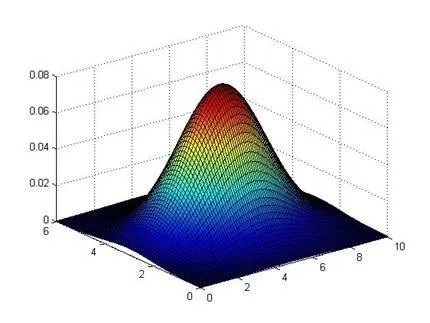
异常检测系统的例子
例如:我们有10000台正常引擎的数据,有20台异常引擎的数据。 我们这样分配数据:
- 6000台正常引擎的数据作为训练集
- 2000台正常引擎和10台异常引擎的数据作为交叉检验集
- 2000台正常引擎和10台异常引擎的数据作为测试集
具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建
函数 - 对交叉检验集,我们尝试使用不同的
值作为阀值,并预测数据是否异常,根据 值或者查准率与查全率的比例来选择 - 选出
后,针对测试集进行预测,计算异常检验系统的 值,或者查准率与查全率之比
异常检测 vs 监督学习
最根本的区别是异常检测基本不需要标签数据,是一个无监督学习算法,使用有标签数据可以调优/验证模型,
两者比较:
| 异常检测 | 监督学习 |
|---|---|
| 非常少量的正向类(异常数据 |
同时有大量的正向类和负向类 |
| 许多不同种类的异常,非常难。根据非常 少量的正向类数据来训练算法。 | 有足够多的正向类实例,足够用于训练 算法,未来遇到的正向类实例可能与训练集中的非常近似。 |
| 未来遇到的异常可能与已掌握的异常、非常的不同。 | |
| 例如: 欺诈行为检测 生产(例如飞机引擎)检测数据中心的计算机运行状况 | 例如:邮件过滤器 天气预报 肿瘤分类 |
注意点
我们这里假设了特征满足1.正态分布,2.且相互独立。对于这两个特点,我们需要对不满足这些条件的数据下面的处理
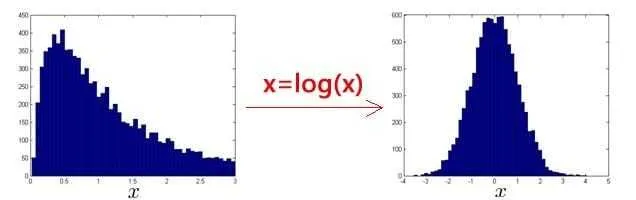
- 非正态分布特征转换为正态分布:,例如使用对数函数:
,其中 为非负常数; 或者 , 为 0-1之间的一个分数,等方法。(编者注:在python中,通常用 np.log1p()函数,就是 ,可以避免出现负数结果,反向函数就是 np.expm1())
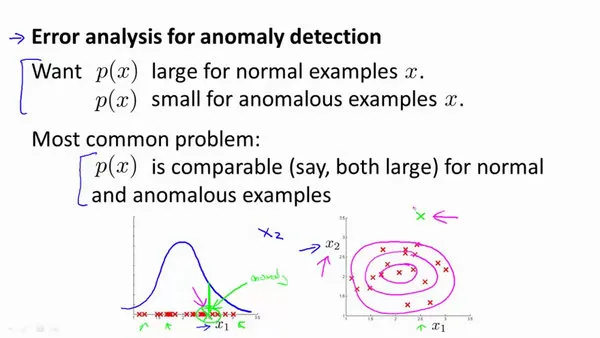
- 不独立的特征:我们经常发现模型一些异常的数据可能也会有较高的
值,这个可能是特征有了问题,一般会使用误差分析的方法,发现一些新的特征--通常可以通过将一些相关特征进行组合,来获得一些新的更好的特征。(简而言之把不独立的特征组合形成一个特征消除了不独立的问题)
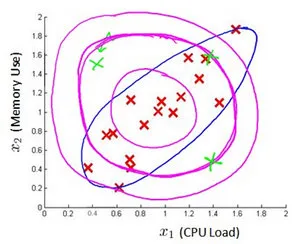
多元高斯分布
解决特征相关的问题一个更『高级』的方法是使用多元高斯分布,他的分布如下图蓝色所示:是一个歪的椭圆
模型表示:
我们首先计算所有特征的平均值,然后再计算协方差矩阵:
- 最后我们计算多元高斯分布的
:
- 当p(x)<ε时,为异常。
注:其中
- $\mu $ 是一个向量,其每一个单元都是原特征矩阵中一行数据的均值。
- $\Sigma $是一个协方差矩阵
模型分布图像如下:最后两个是多元混合才能有的效果,前两个普通的高斯分布即可
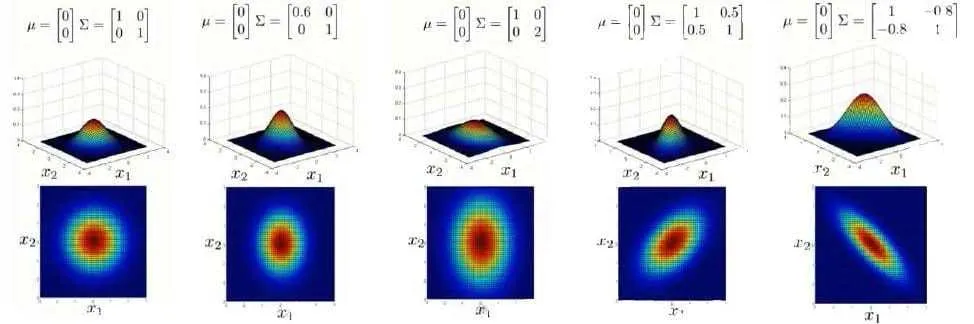
上图是5个不同的模型,从左往右依次分析:
- 是一个一般的高斯分布模型
- 通过协方差矩阵,令特征1拥有较小的偏差,同时保持特征2的偏差
- 通过协方差矩阵,令特征2拥有较大的偏差,同时保持特征1的偏差
- 通过协方差矩阵,在不改变两个特征的原有偏差的基础上,增加两者之间的正相关性
- 通过协方差矩阵,在不改变两个特征的原有偏差的基础上,增加两者之间的负相关性
原高斯分布模型是多元高斯分布模型的特殊情况,他们的应用场景区别如下:
原高斯分布模型和多元高斯分布模型的比较:
| 原高斯分布模型 | 多元高斯分布模型 |
|---|---|
| 不能捕捉特征之间的相关性 但可以通过将特征进行组合的方法来解决 | 自动捕捉特征之间的相关性 |
| 计算代价低,能适应大规模的特征 | 计算代价较高 训练集较小时也同样适用 |
| 必须要有 |
原高斯分布模型被广泛使用着,如果特征之间在某种程度上存在相互关联的情况,我们可以通过构造新新特征的方法来捕捉这些相关性
多元高斯分布应用过程如下:

推荐系统
基本思路:
- 先假设每个电影有一组隐含的特征(
),每个用户j对i电影的评分可以理解成一个线性模型,模型参数是 ,表示用户的偏好,即 ,因此进一步有线性模型的cost函数: - 上面是针对一个用户的,那么对于所有
个用户,代价函数如下: - 我们可以使用梯度下降发求解这个大的代价函数(前提是隐含特性
已知) - 但是我们并没有电影的特征
,这里我们不直接去找这些特征,而是从另一个角度构建用户维度的模型(上我们称作内容维度模型) - 再假设我们有用户的隐含特征
,我们可以学习得出个电影i评分的参数 (注意与1对比,什么是自变量)。那么所有 个电影的代价函数如下:$$\mathop{min}\limits_{x^{(1)},...,x^{(n_m)}}\frac{1}{2}\sum_{i=1}^{n_m}\sum_{j{r(i,j)=1}}((\theta^{(j)})^Tx^{(i)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{i=1}^{n_m}\sum_{k=1}^{n}(x_k^{(i)})^2$$ - 但是我们既没有电影参数
,也没有用户参数 ,这里就使用了协同过滤。首先我们修改优化目标为上面的和 对他求导结果: - 协同过滤梯度下降的核心就是先固定一组参数,求另一组参数,然后再反过来,如此反复迭代收敛
具体算法和向量化实现参考讲义
注意点:均值归一化
对用户对每个电影的评分减去平均分后训练算法
预测时再加回来,这样有个好处,即使用户没有任何数据,他的初始数据就是电影的平均分,按这个给他推荐也不太离谱
大规模机器学习(大数据集)
在面对大型数据集的时候,我们上面讨论的一些方法不再可行,典型的是:梯度下降算法(批量梯度下降),首先每一步更新
为什么使用大数据集,何时使用,之前在学习曲线、方差的时候讨论过
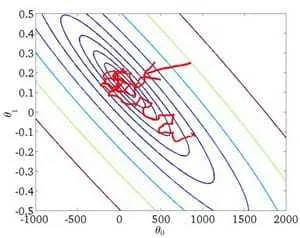
使用随机梯度下降代替批量梯度下降
核心:每次使用一个数据样本更新所有的n个参数
Repeat (usually anywhere between1-10){
for
}
}
特点:每一次迭代未必走向最优,甚至会劣化代价函数,但是会『跌跌撞撞』走向优化的位置
mini-batch
核心:结合随机梯度下降和批量方法,使用每次使用b个数据样本更新所有的n个参数
Repeat {
for
$ i +=10 $
}
}
优点:一次计算b个数据样本,
如何观测随机梯度下降
我们在批量梯度下降时,每次迭代后通过计算代价函数J来指导当前算法运行的方向/效果是否符合预期。当使用随机梯度下降时,如果用一个样本的训练结果来计算J,会发现波动极大,以至于不能很好的观测算法的运行方向。更好的方法如下
- 我们在每一次更新
之前都计算一次代价 - 然后每
次迭代后,求出这 次对训练实例计算代价的平均值, - 然后绘制这些平均值与
次迭代的次数之间的函数图表。
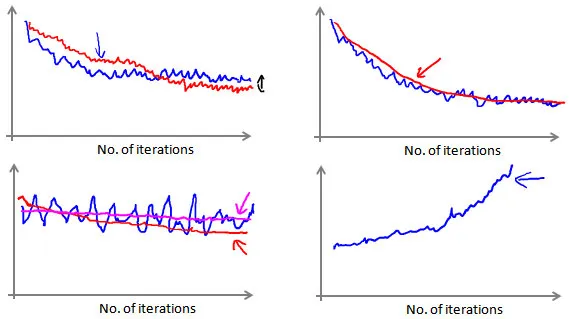
我们可以通过增大上面的
,来平滑曲线,如左下角所示:蓝色与红色对比
我们期望的结果是不断减小(如上面的2个图),如果出现图4的情况,说明算法有问题
使用并行化计算(映射化简)
类似MR的思想
- 多台机器并行:之前提到,如果我们用批量梯度下降算法来求解大规模数据集的最优解,我们需要对整个训练集进行循环,计算偏导数和代价,再求和,计算代价非常大。如果我们能够将我们的数据集分配给不多台计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样的方法叫做映射简化。
- 多核并行:此外,上面用的线性代数库是在多核基本的并行
在线学习
我们可以把随机梯度下降的思想用到流式的机器学习:
- 数据是一个一个到来的,类似与随机梯度下降里面的一个数据样本
- 数据是无限的,源源不断的。所以用完就可以丢弃,这与随机梯度下降不同(它会重复使用数据集)
- 适应性:在线学习会更具用户的变换模型自动的改变调整来适应新的情况
Repeat forever (as long as the website is running) {
Get
(for
}
如何搞定一个复杂的机器学习项目:以OCR为例
问题:识别图片中包含的所有文字

问题拆解形成流程图
为了完成这样的工作,需要采取如下步骤:
- 文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
- 字符切分(Character segmentation)——将文字分割成一个个单一的字符
- 字符分类(Character classification)——确定每一个字符是什么
可以用任务流程图来表达这个问题,每一项任务可以由一个单独的小队来负责解决:

过程分析--关键技术:滑动窗口
上面的1,2中都涉及一个关键的技术
滑动窗口是一项用来从图像中抽取对象的技术。假使我们需要在一张图片中识别行人,首先要做的是用许多固定尺寸的图片来训练一个能够准确识别行人的模型。然后我们用之前训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁,然后将剪裁得到的切片交给模型,让模型判断是否为行人,然后在图片上滑动剪裁区域重新进行剪裁,将新剪裁的切片也交给模型进行判断,如此循环直至将图片全部检测完。
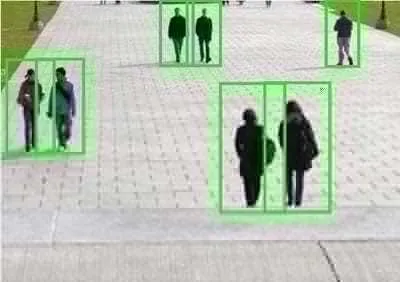
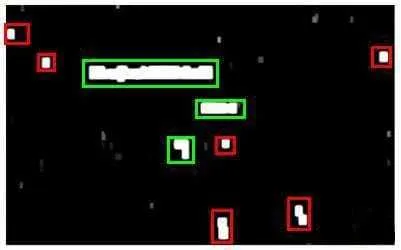
文字区域侦测:
- 训练模型,判断字符还非字符
- 使用滑动窗口扫描图片(单个字符的尺寸以及缩放的单个字符尺寸,比例固定)
- 字符重叠区域合并
- 接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(认为单词的长度通常比高度要大)
效果如下(绿色为最终有效区域)
字符切割:
- 训练一个模型来完成将文字分割成一个个字符的任务,正负样本如下图
- 使用滑动窗口技术来进行字符识别


字符分类:这个比较简单,直接用神经网络
如何获取样本
训练模型时我们需要收集样本,获取样本的手段有下面几种
- 人工数据合成:优先推荐,低成本。如上面的例子收集字体样本可以去网上找各种字库,基于这些数据然后修改这种字体,做各种变形,形成新样本
- 手动收集、标记数据
- 众包
上限分析
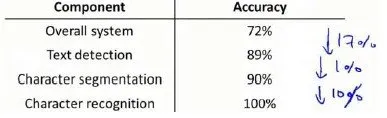
当遇到问题时怎么办?典型的无法进一步提升准确召回,如何才能优化模型?我们需要对各个阶段进行分析,找出可以优化点,并能预估出这样做大概能有多少的提升,把有限的精力放到最有价值的地方。以上面的pipeline为例,流程图中每一部分的输出都是下一部分的输入,上限分析中,我们选取一部分,从第一步开始手工提供100%正确的输出结果,然后看应用的整体效果提升了多少。假使我们的例子中总体效果为72%的正确率。
- 如果我们令文字侦测部分输出的结果100%正确,发现系统的总体效果从72%提高到了89%。这意味着我们很可能会希望投入时间精力来提高我们的文字侦测部分。
- 接着我们手动选择数据,让字符切分输出的结果100%正确,发现系统的总体效果只提升了1%,这意味着,我们的字符切分部分可能已经足够好了。
- 最后我们手工选择数据,让字符分类输出的结果100%正确,系统的总体效果又提升了10%,这意味着我们可能也会应该投入更多的时间和精力来提高应用的总体表现。