Spark相关论文如下:
- Spark: Cluster Computing with Working Sets
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction forIn-Memory Cluster Computing
Spark: Cluster Computing with Working Sets
这篇文章有些内容过时了,如当时不支持shuffle,但是基本的思想可以借鉴。
简介
- mr模型是用来处理acyclic data flow的,但是,有时候我们想要在一个数据集上执行多次操作( reuse a working set of data across multiple parallel operations):
- 具有迭代操作的应用
- 交互式应用
- spark查询39GB数据不要1s,10x的速度对比hadoop
- 数据并行计算框架的基本能力,可以自动处理下面这些复杂度:
- scalability
- locality-aware scheduling
- fault tolerance
- load balancing
- spark的提供了并行计算框架的基本能力(学习如何实现)、
- spark提供了抽象概念的RDD
- 只读的
- 跨机器的(scalability)
- 自动rebuild(fault tolerance),通过血统(lineage)
- 可以手动cache
- RDD不是通用的一个分布式共享内存的抽象,他为了实现可靠性和可扩展,牺牲了通用的表达能力(就是我们不能把rdd看成分布式缓存)
- 使用scala实现
编程模型
程序组成:
- 我们只写driver程序,控制整个app
- 两个并发编程的抽象:
- 数据集:resilient distributed datasets
- 数据集上的并行操作:parallel operations on these datasets -- 一个发送给数据集的function
- 此外,还有两个共享变量
- 数据集RDD
- 特性:只读&&自动重建(fault tolerance)
- 如何构造RDD,RDD是一个scala的对象
- 从parallelizing:数组
- 从文件:hdfs
- 从已有RDD转化:flatmap map filter ,注意:spark内部只要实现flatmap即可,map filter可以用flatmap实现
- 通过更改现有RDD的持久性
- cache:如果数据集太大,或者丢失,自动重算
- save
- 未来可能支持其他方式的缓存,如多副本缓存。
- 数据集上的并行操作
- 支持的操作
- reduce:在driver产出一个结果
- collect:在driver收集所有的数据
- foreach:执行分布式的操作,会产生副作用
- 不支持多个reduce,并发,比如执行按某个key的group时,只能聚合到driver一个节点。未来需要支持shuffle来支持这种操作。
- 共享变量
- 为什么需要:上面的map,filter,reduce都是传递/copy一个函数闭包到某个节点上执行,只能处理本节点自己创建的变量,我们可能需要一些共享的信息。
- Broadcast variables:只读的,传递一个大的查找表,且确保每个节点只专递一次。
- Accumulators:提供『加』语意(包括zero),任何节点可操作,只有driver可读。
编程例子
- 文本搜索过滤:cache
- LR:accumulator
- ALS:broadcast
实现
RDD
- spark是建立在mesos之上的,mesos是一个『集群操作系统』,在上面协议跑各种分布式的框架,hadoop、mpi等,当然可以实现spark
- 可以用mesos的api启动task
- 共享机器资源
- 实现spark的核心是实现『RDD』
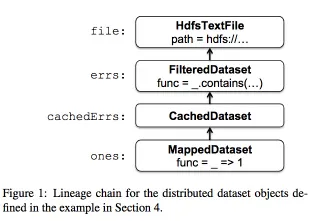
- 数据集在spark中表示成一串scala的object:他们表示了** the lineage of each RDD**,且每个对象包括
- 一个指向他parent的指针
- parent如何转换为这个RDD
- 所有RDD都实现了的一组相同的接口:
- getPartitions:获取所有分区ID的List
- getIterator(partition):获得一个分区恩迭代器
- getPreferredLocations(partition):用于数据的本地调度
- 当我们执行『并行操作』时,会
- 创建一个task来处理数据集的每个分区。
- 发送这个task到每个worker节点:会尽量发送到preferred locations。使用『delay sheduling算法』来获得本地调度。
- 在worker上调用getIterator读取数据
- 不同类型的RDD,只是实现上面的接口不同
- HdfsTTextFile
- getPartitions:分区是block的id
- getPreferredLocations:就是block的位置
- getIterator:一个stream流
- MappedDataset
- Partitions、PreferredLocations:同上
- Iterator:就是应用mapper func到上面的steam
- CachedDataset
- getIterator:查找本地内存有没有transformed partition的副本。
- PreferredLocations:一开始就是parent的PreferredLocations。在cached之后会更新为内存存储的node
- 如果存储fail,会重新读取parent的数据,再cache到其他node
- 发送task到worker上,就是发送closure(以及闭包bound内的变量),
- 发送的内容具体而言包括:
- 定义数据集的闭包:RDD?
- 操作相关的闭包:如reduce
- 使用java序列化scala/java的object来发送
- 理论上比较简单直接发送对象就行
- 实际上,scala的闭包实现有bug,会把闭包内没有引用obj打包进来,他们通过分析字节码把没有用的变量设为null
共享变量
- broadcast and accumulators 各自都使用了『自定义的序列化格式』
- broadcast:以具有值v的广播变量b为例
- v存储在一个『共享文件系统』中(初始版本用的是HDFS,正在开发高效的流式广播系统)
- b的序列化方式就是一个文件路径,指向v
- 当worker查询时,会读取共享文件的路径下的数据,并把数据缓存到本地内存。
- Accumulators
- 先在driver上序列化了Accumulator的数据结构,他含有:
- 唯一的ID
- 类型定义的初始『zero』值
- 在每个worker节点上为每个运行task的线程复制一个ThreadLocal的Accumulator变量,也是初始为zero
- task运行结束后,发送Accumulator到driver,进行合并
- 对某个Accumulator的操作的更新,每个partition只会执行一次。防止重新执行的task多次计算相同的值。
继承Scala解释器实现交互查询
- scala交互解释器实现原理:
- 用户输入的一行都编译成一个class,这个类包含一个单例object,如
var x = 5会编译成class Line1 println(x)会翻译成println(Line1.getInstance().x)
- spark对他的修改
- 每一个class定义都输出到一个共享文件系统中,目的是在其他机器上的节点可以使用(通过java classloader加载)
- We changed the generated code so that the singleton object for each line references the singleton objects for previous lines directly, rather than going through the static getInstance methods. This allows clo-sures to capture the current state of the singletons they reference whenever they are serialized to be sent to a worker. If we had not done this, then updates to the singleton objects (e.g., a line setting x = 7 in the ex-ample above) would not propagate to the workers
Resilient Distributed Datasets: A Fault-Tolerant Abstraction forIn-Memory Cluster Computing
简介
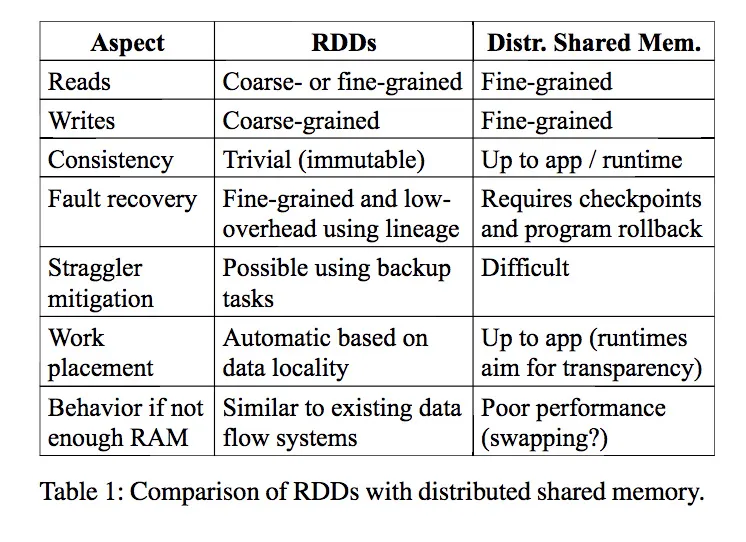
- 为了错误容忍,RDD提供了一种『受限的共享内存』:他是基于粗粒度的transformation,而不是细粒度的对共享状态的update。
- 对比DSM:distributed shared memory(如key-value stores)是操控数据表中的可变状态(是一个任意地址位置的值)。他要错误容忍,必须副本+log update。对于数据密集型应用这是不可接收的:需要大量额外空间和传输带宽。
- 对比RDD:logging the transformations used to build a dataset (itslineage) rather than the actual data
- rdd的特征
- 错误容忍(最重要的,也是最大的挑战)
- 并行的数据结构
- 可以缓存用户指定的中间数据
- 可以控制数据分区(partition),优化数据存放位置。(相比于前一篇论文的新内容)
- 提供了丰富的操作
- 性能(对比hadoop)
- iterative应用:20x,如LR算法
- 交互式数据分析:40x(1tb数据5-7s)
错误容忍的两种方式
- 数据密集型--基于转换方式--spark
- 计算密集型--副本方式--数据库,kv存储
rdd概览
-
创建RDD:
- data in stable storage
- other RDDs
-
transformations:map, filter, and join
-
RDD具有lineage:information about how it was derived from other datasets (its lineage) to compute its partitions from data in stable storage.
-
用户可以控制的RDD的两个重要属性:
- persistence :是否持久化cache,以便重复使用rdd
- partitioning:如何根据key分布数据(hash-partitioned,可以自己设置partitioner)
-
编程接口:
- transformations:他是lazy的
- actions
- persist方法,可以选择persistence strategies(前一篇论文中提到会加上)
-
demo
- 自动pipeline,连续的map filter 会自动合并为一个task
-
RDD模型的优点(对比DSM)
- 只能通过Transformation创建(批量 bulk write)新的RDD
- 更高效容错,
- 不需要checkpoint(在依赖很长是也用checkpoint,但是可以异步后台运行)
- 只需要恢复、重算丢失部分数据,而不是全量恢复
- 更高效容错,
- 数据的不可变性
- 可以优化长尾任务,迁移慢节点,DSM中由于副本可能不一致,导致很难迁移
- 由于批量操作,所以可以按照位置调度任务,提速
- 对于scan操作,内存不够时也能优雅降级,用stream读磁盘
- 只能通过Transformation创建(批量 bulk write)新的RDD
The main difference between RDDs and DSM is that RDDs can only be created (“written”) through coarse-grained transformations, while DSM allows reads and writes to each memory location.
- RDD模型的缺点(DSM适合)
- 不适合非批量任务,如web应用更新表,
- 不是和异步任务的细粒度update,爬虫抓取数据入库
spark编程接口
- spark是scala开发,API类似DryadLINQ
- 快:静态类型
- 便捷:支持交互式
- spark架构,用户写driver,连接n个worker
- driver上的RDD跟踪整个lineage
- worker是常驻进程,可以在内存中存储RDD的各个分区
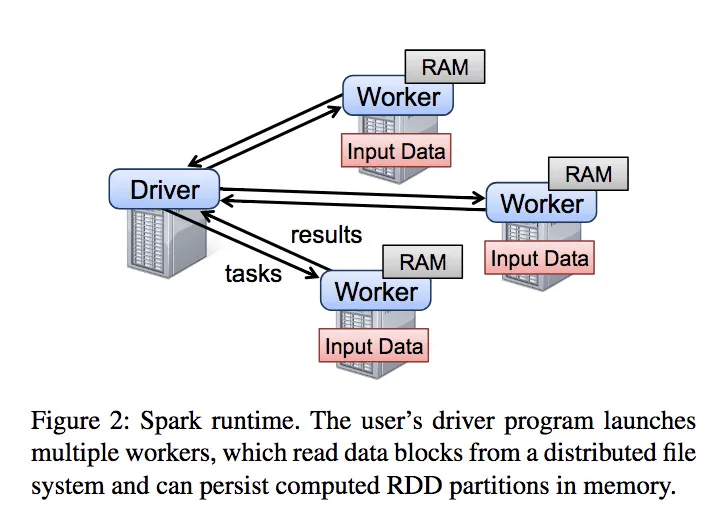
- 用户通过rdd操作的参数(如map的参数)传递闭包,这个闭包就是个java的object,可以序列化,然后传输到其他node上,再加载运行。(注意也会序列化闭包依赖的变量,一个注意点:变量一斤发送,再修改变量,发送的闭包里的值不会变化)
- RDD是有类型的如RDD[Int],但是我们一般不用在意,scala会自动类型推断。
- 虽然原理很简单,但是scala的闭包有些问题需要修改(使用反射修改的),如果用交互模式,也需要一些修改,但是不需要修改scala编译器。(之前的论文也提到过)
RDD的操作(operation)

注意点:
- transformations是lazy,action才是真正运算
- 一些操作如join, 只在key-value pairs的RDD上有用
- 其他的命中竟然与函数式编程的一直,可以发现:这里的flatmap就是hadoop的map函数。
- 除此之外,还有
- persist操作
- 用户可以获得RDD的partition order,他用
Partitioner类表示。用来表示数据如何分区。groupByKeyreduceByKeysort`会生成一个hash/range分区的RDD。
例子
-
例子1:LR算法
- cache的应用
-
例子1:PageRank(重点)
- 理解算法,同时看一下RDD的图谱。
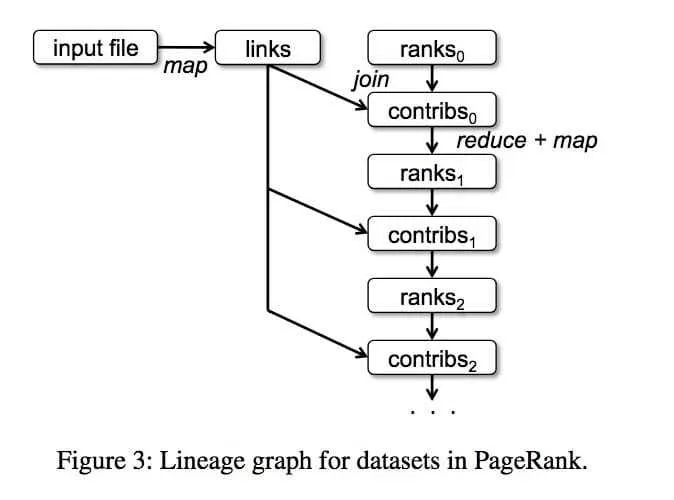
- 几个优化要点(对于多次迭代的应用通用)
- 缓存ranks,而不要缓存links。原因:links重新生成的成本小,且数据集很大,没必要缓存
- ranks的缓存,persist使用
RELIABLE的flag。因此迭代运算成本高,一旦丢失重算非常耗时,所以可靠缓(内部可能缓存了多副本)存每一步生成ranks,而且ranks占用空间很小。(当然旧的ranks可以手动抛弃) - 使用url作为partitioner的可以来join的优化:由于多次迭代,每一步都要join,都shuffle太慢。可以手动设置分区,只在第一次运行时按照url分配好位置,以后的join都是本地运行,只shuffle一次,
links = spark.textFile(...).map(...).partitionBy(myPartFunc).persist()
注意:一些其他系统如
Pregel,会对这种多次迭代时保持数据分区的一致,这是他们的一个重要优化功能。spark这里交给用户自己选择。 - 理解算法,同时看一下RDD的图谱。
RDD的实现
论文中说RDD是 a simple graph-based representation (基于图的表示)
设计一:如何表示RDD
RDD的表示通过暴露5个信息(5个接口方法)来实现
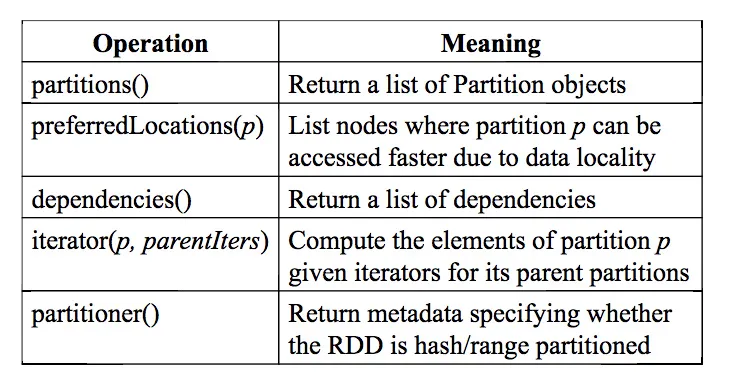
a set of partitions, which are atomic pieces of the dataset;
a set of dependencies on parent RDDs; a function for computing the dataset based on its par-ents; and metadata about its partitioning scheme and data placement.
- 一组partitions:partition是数据集的最小组成结构 --
partitions() - 一组dependencies:记录所有父RDD --
dependencies() - 一个函数:用来从父亲计算出他自己--
iterator(p,parentIters) - 数据分区方式的meta信息 --
partitioner() - 数据分布的信息 --
preferredLocations(p)
设计二:如何表示RDD的关系
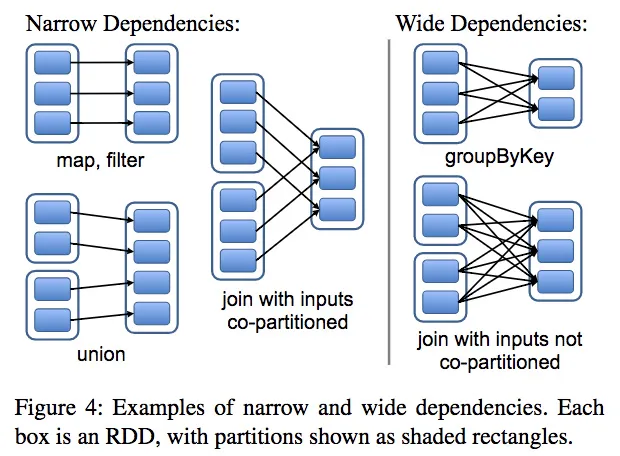
把RDD间的关系定义为下面两类
- narrow dependencies: each partition of the parent RDD is used by at most one partition of the child RDD
- wide dependencies: multi-ple child partitions may depend on it
例子:
- map就是窄依赖
- join(除了parent都是hash partitioned的情况)就是宽依赖
两种关系的特点
- narrow -- pipeline执行,易于恢复,只要重算失败的父节点
- wide -- shuffle,恢复需要重算所有父节点
RDD实现demo
- hdfs files:读取hdfs文件生成的RDD
- paritions:每个文件block是一个partition(包括offset存储在Partition对象中)
- preferredLocations:就是文件存储的节点
- iterator:读取block
- map:map操作转换生成的RDD(MappedRDD)
- paritions:与parent相同
- preferredLocations:与parent相同
- iterator:使用func处理parent的记录
- union
- paritions:所有parent的partitions的合并
- sample:与map相同,RDD为每个partition存储一个随机数生成器的seed
- join:
- 有以下三种情况
- 两个窄依赖
- 一个窄依赖,一个宽依赖
- 两个宽依赖
- 他的输出必定有一个partitioner(继承parent的partitioner,或者是默认hash-partitioner)
- 有以下三种情况
其他实现
Each Spark program runs as a separate Mesos application, with its own driver (master) and workers, and resource sharing between these applications is handled by Mesos.
job 调度
- 当运行action时,scheduler检测RDD的lineage,生成一个stage的DAG图
- 每个stage内部是尽量多的窄依赖的操作,可以pipeline执行---合并形成一个task?
- stage的边界是宽依赖,执行shuffle操作
- 任何已经计算完成的分区(如cached过的)可以短路parent RDD的计算、
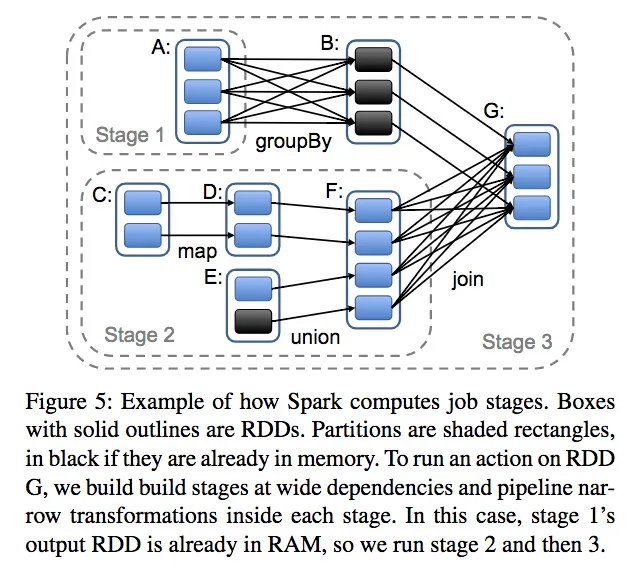
- scheduler基于数据本地性,调用task(delay schedule算法)
- 如果数据在某个node的内存中,直接发送给该node运行
- 否则,如果改partition有preferred的位置,直接发送给他。
- 对于宽依赖,会在存有父partition的node上暂存shuffle的中间记录,就想MR会暂存map的output一样
- 如果task失败,会寻找stage(因为合并吗?)的parent。(结合宽依赖都会暂存记录,所以应该能找到)如果找不到结果则需要重算上一个stage。
未解决问题:
- 当前还不支持scheduler的失败恢复,但是这个实现起来比较简单,只要保持他的RDD lineage图就行
- 当前所有的action都是由driver发出的,只在需要在driver程序中检测partition是否存在并操作schedule。以后可能需要在map中(worker)有查找lookup操作???? 在每个task里面执行lookup?这就需要每个task都能通知shedule?
整合解释器
略,基本与上一篇的解释一致,问题还是Modified code generation的意义
checkpoint机制
RDD lineage虽然可以用来恢复失败任务,但是,如果在RDD链条很长的情况下,恢复重算非常费时间。尤其是存在宽依赖的场景,下游的一个task失败,导致上游大量重算。如之前的RankPage的例子。
这里,我们需要用户通过手动添加RDD的persist的REPLICATE flag来告知系统用多副本方式缓存RDD,防止中间结果丢失。
未解决问题:
- 自动选择合适的RDD来多副本备份(理论上是可以做到的)
中文参考文章
http://itindex.net/detail/51871-spark-rdd-模型
I
lazy问题:
read rdd时是lazy?
cache是lazy?
cache问题:
shuffle的rdd,宽依赖是否会自动cache?(有人说是的)。cache在哪里(论文中说在父节点?类似MR?)
每一个RDD可以设置persistence priority?什么
LRU策略具体是什么
操作问题:
论文中说以后会提供一个在map里面的lookup操作?是什么鬼?
论文中说会有自动的checkpoint(persist(REPLICATE)还)
架构问题
调度起schedule具体是个什么东西
shuffle论文:Managing Data Transfers in Computer Clusters with Orchestra
分为两个部分 broadcast和shuffle。看了shuffle部分
shuffle
基本结论如下
- shuffler的优化准则(从receiver角度看):an optimal shuffle schedule keeps at least one link fully utilized throughout the transfer(在receiver和sender间是单条路由的情况下,这是充要条件,多路的情况下是必要条件),这告诉我们
- 理论上receiver只要一个一个的读取sender的数据(如果每一个能保持跑满带宽),就可以或者最优解。因此一个简单的方案就是每个receiver随机读一个sender,读完就换下一个。
- 上面这个方案有个风险就是存在多个receiver只读一个sender,导致跑不满带宽,因此建议使用一个reveiver读取多个sender。
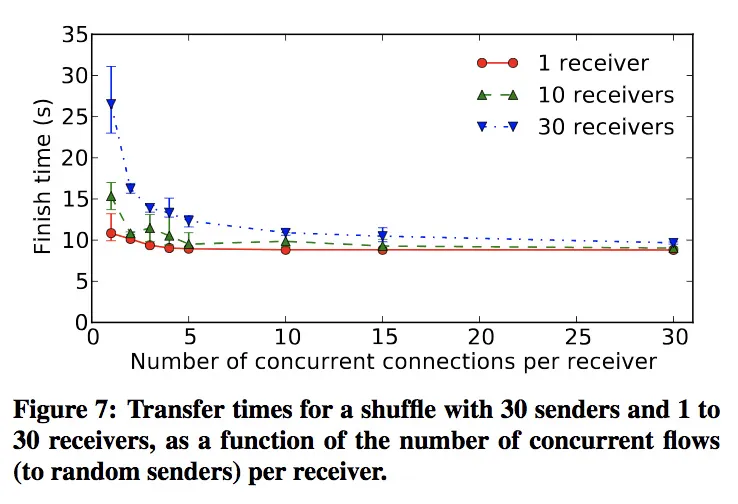
- receiver端读取sender时,应该同时读取多个sender的数据(hadoop中使用了5,spark0.5中默认的fetcher是1个,有个优化的类是3个),参见下图的横轴和竖轴,竖轴是完成时间(竖的线段是抖动范围)
- 每个receiver读取单个sender时,随着receiver数目的增多,性能变差,参见下图中不同颜色的线
优化方案(没有实践)
- 加权带宽方案,对于数据倾斜的sender,receiver分配带宽时,增加他的权重(按照数据量的比例分配)
- 带宽权重的分配方法是带权重的max-min fairness算法
- 问题是:
- 这个只是解决了receiver端的带宽分配,没有考虑sender的总带宽(这里假设他很大)
- 也没有考虑receiver慢节点的问题,这个无解,他必定会拖累整个shuffle
- 在数据分布均匀的时候和fair调度效果一样
- 按照数据量分配带宽实现起来也很坑,一个是需要数据量的信息,一个是tcp的带宽控制
- 总之,这个方法很少有人用
http://www.mosharaf.com/wp-content/uploads/orchestra-sigcomm11.pdf