分析spark初版本的源码,代码行数1w+,比较简单,但是基本架构变换不大,有必要阅读。先提出阅读Spark论文的一些疑问,再阅读源码。
阅读论文的问题
RDD
- 如何构造RDD(4中方式)
- 从paralize
- 从hdfs
- 从已有RDD转化
- 通过将已有的RDD持久化?(直接用内存的RDD)
- 如何缓存--如何存放比物理内存大的RDD(对比虚拟缓存)
- 如何高效的错误容忍:节点失败了,RDD如何重建---继续运行不出错
- 粗粒度转换(coarse-grained transformation)的接口
lazy问题
- read rdd时是lazy?
- cache是lazy?
cache问题:
- shuffle的rdd,宽依赖是否会自动cache?(有人说是的)。cache在哪里(论文中说在父节点?类似MR?)
答:不会,但是会落盘。 - 每一个RDD可以设置persistence priority?什么
- LRU策略具体是什么
操作问题
- 论文中说以后会提供一个在map里面的lookup操作?是什么鬼?
- 论文中说会有自动的checkpoint(persist(REPLICATE)还)
- join操作的实现,是否使用broadcast?
架构问题
- 调度起schedule具体是个什么东西
start
以 sc.parallelize(data, numSlices).count 这个最简单的例子为例,学习流程
阅读sparkContext
构建&&初始化一些重要的变量
- 构建SparkEnv(ThreadLocal中)
- 构建Cache:
BoundedMemoryCache extends Cache - serializer:
JavaSerializer extends Serializer - cacheTracker:
CacheTracker(参考下面Cache设计要点)- 在master上启动一个
CacheTrackerActor(extends DaemonActor) - 在worker上会连接master的Actor
- 注意CacheTracker类中定义了缓存&&计算(
getOrCompute)的逻辑!!
- 在master上启动一个
- mapOutputTracker:记录了每一个maper的输出的位置信息,下面的fetcher会用。
- shuffleFetcher:读取方法,获取远程的shuffle数据
- shuffleMgr:每个worker上都会有(master也有?),提供了shuffler的文件获取http服务
- 构建Cache:
- Broadcast.initialize
- 构建Scheduler
- Methods for creating RDDs
- Methods for creating shared variables
runJob函数
该函数是运行任务的入口,触发的Action都会调用该函数触发计算:stage划分,task生成,提交task到集群
读取输入数据函数
形成输入数据的RDD
- parallelize:内存的数据输入,比较特殊
- textFile:调用了hadoopFile获取hdfs上的文件
- hadoopFile、HadoopRDD
object SparkContext内定义隐式转换
contains a number of implicit conversions and parameters for use with various Spark features.
SparkEnv内重要的组件
Cache设计要点
每个exector上已有一个Cache实例,
- 存储both partitions of cached RDDs and broadcast variables (存储RDD的分区和广播变量)
- Caches are also aware of which entries are part of the same dataset (可以区分出不同的partition是不是同一个dataset的)
- key是(datasetID, partition) ,这里的datasetID包含了命名空间(Space)信息
key的设计--KeySpace
原因:每个exector上已有一个cache实例,所有模块共享,需要区分命名空间
实现:
- 使用了一个int的keySpaceId来区分:(datasetID, partition) 其中:datasetID=(keySpaceId, datasetId) 这里datasetId是真实的id
- 实现Cache的接口的子类的key都是被KeySpace处理过的。
cache对象大小评估--SizeEstimator
- Estimates the sizes of Java objects (number of bytes of memory they occupy), for use in memory-aware caches.
- 原理 http://www.javaworld.com/javaworld/javaqa/2003-12/02-qa-1226-sizeof.html
- limitations; most notably, we will overestimate total memory used if some cache entries have pointers to a shared object
jvm内存分配 -- Runtime.getRuntime.maxMemory
https://stackoverflow.com/questions/23701207/why-do-xmx-and-runtime-maxmemory-not-agree
内部表示-LinkedHashMap(存储顺序与读取一致):
原因:实现LRU order
注意:
- LinkedHashMap的线程安全问题
- get逻辑(一次get一个partition)
- 比较简单就是map的get,注意key
- put逻辑(一次put一个partition)
- 判断空间足够,直接put(可能覆盖相同的cache--重复put)
- 判断无法放下(
ensureFreeSpace):需要的空间小于剩余空间&&查找到自己的datasetId(rdd.id),这说明:- 其他的rdd的所有分区已经都删除了,都放不下他。(可能这个rdd的其他partiton已经放了,这肯定是最新的!)
- 或者,曾经cache过这个rdd(已经放下--重复put)
- 注意:这里的逻辑保证了即使空间不够放下rdd的所有分区,也能尽量放入一部分分区。
理解LRU设计逻辑
Cannot make space without removing part of the same dataset, or a more recently used one
https://blog.csdn.net/luanlouis/article/details/43017071

总结
- cache的基本架构,driver的Actor服务 + 每个exector想他汇报信息
- 如何实现缓存,LRU,所以我们不需要手动uncache,具体实现在Cache极其子类中
- 添加缓存的过程:
- rdd中cache(driver中),设置标记位
shouldCache,并不会立刻缓存,表示该rdd触发action运算时请缓存数据。 - 发起位置(已经在executor中):在rdd的
iterator函数中,如果需要缓存调用SparkEnv.get.cacheTracker.getOrCompute[T](this, split) - CacheTracker的getOrCompute函数是核心逻辑:判断是否已经缓存,没缓存时,调用rdd.compute()执行计算并缓存
- 成功后,通知driver上的trackerActor(AddedToCache消息)
- driver上的trackerActor,统计信息并几率缓存位置(hashmap:(rdd_id,partition)->host)
iterator函数何时调用?参考下面的schedule
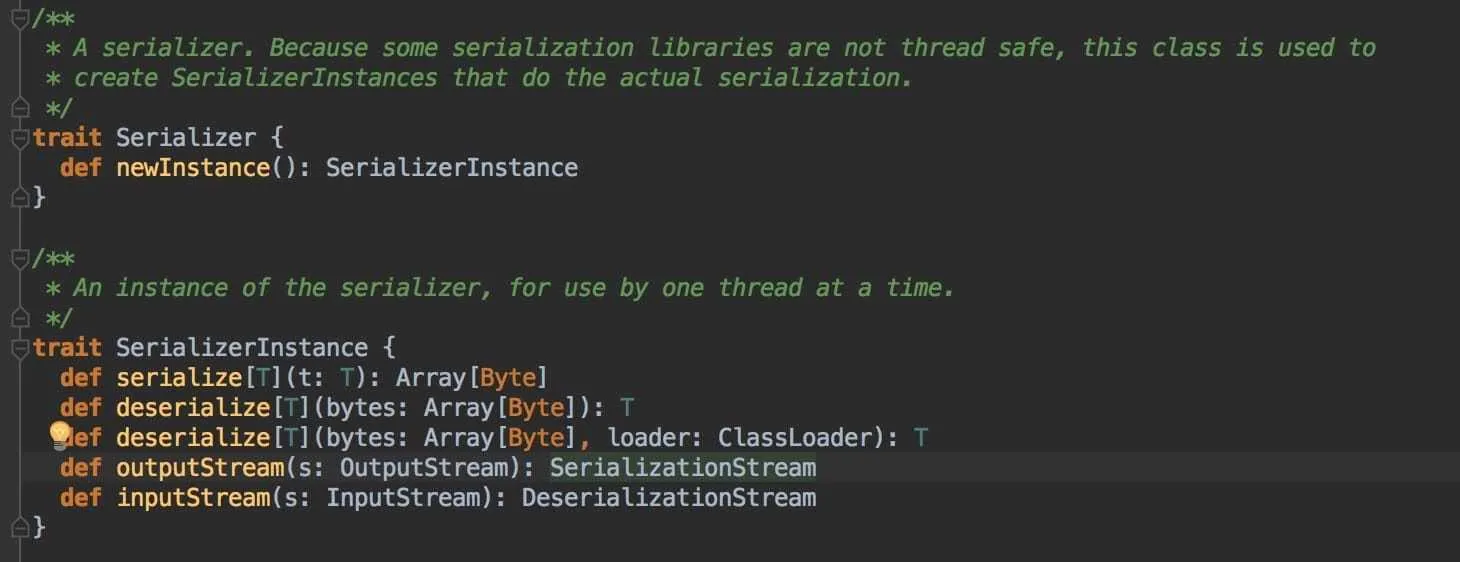
Serializer
线程安全的序列化封装,返回一个序列化工具的实例SerializerInstance,该接口是序列化相关的方法,one instance used by one thread at a time.
使用时val ser = SparkEnv.get.serializer.newInstance()
疑问:
效率低吗?每次都是构建了一个新的实例,不过一个线程一个实例其实还好
CacheTracker
wait&¬ify并发编程
rdd.compute(split).
MapOutputTracker
ConcurrentHashMap
什么是generation?
SimpleShuffleFetcher
重点逻辑
- master保存了shuffle的元信息:var serverUris = new ConcurrentHashMap[Int, Array[String]]
- 获得数据:·
val url = "%s/shuffle/%d/%d/%d".format(serverUri, shuffleId, i, reduceId)- serverUri:上游机器地址
- shuffleId:对应一个shuffle任务
- i:某个shuffle任务的一个map的输出的mapid【0,1,2....】
- reduceId,map端reduce处理后的分配好了的给reduce的id。
- 每个shuffle数据块格式:total_count[int] + n*object[K,V]
- func(pair._1, pair._2)
- 异常处理
- 每个块最多try 4次
- FetchFailedException
Schedule
action代码运行过程:
action(如rdd.count()) --> sc.runjob(业务逻辑函数作为参数) --> schedule.runjob(DAGScheduler) --> schedule.submitTask(LocalScheduler)
Scheduler:
- DAGScheduler--核心调度算法=根据RDD生成Stage,根据Stage生成Task,按顺序调度Task
- LocalScheduler--具体运行task(线程池) + 通知完成
- MesosScheduler
总结:核心逻辑都在DAGScheduler的runJob函数中
- 根据RDD生成Stage:参考下面Stage与Dependency/RDD的关系
- 根据Stage生成Task:参考下面Task与Stage
- 按顺序调度Task:参考下面Task与Stage
生成DAG的Stage图 -- newStage-getParentStages函数,递归调用,使用了rdd.dependencies判断ShuffleDependency/Narrow
- 除了finalRDD,其他窄依赖的RDD不会生成Stage
提交任务 - getMissingParentStages:从finalStage向前向前查找missing
等待任务完成 -- wait(timeout)+notify
查找表
shuffleToMapStage:更具shuffleid
idToStage
理清Dependency与RDD的关系:
- Dependency表示一般情况下表示两个RDD之间的依赖联系,因此
xxxRDD的变量dependencies表示这个RDD的n个上游的依赖的RDD,假设每个Dependency里面有个变量yyyRDD,就表示xxxRDD与yyyRDD之间的关系,Dependency的子类包括- NarrowDependency:他又有子类
OneToOneDependencyRangeDependency。表示两个RDD之间可以合并的窄依赖关系。 - ShuffleDependency :表示两个RDD之间必须经过shuffle才能关联的关系。
- NarrowDependency:他又有子类
- 使用窄依赖的最后一个rdd作为
ShuffleDependency的包含的RDD - 用图的数据结构来理解:
- RDD是图中的节点。
- Dependency是图中的路径,是一个向前指针(xxxDependency里面包含的rdd就是指向上游节点)。路径又两种不同类型。
Stage与Dependency/RDD的关系(重点!!):
Stage是对上述的图的一种合并&&划分,代码逻辑如下:
- 构建finalStage,即执行Action的最后一个RDD作为Stage
- 从finalStage开始从后往前遍历图。
- 遇到NarrowDependency,不用管,继续向前遍历。本质上,结合窄依赖的合并原理,这一步合并所有的连续NarrowDependency
- 遇到ShuffleDependency,生成新的Stage(代码里命名为ShuffleMapStage)。Stage包括:
- ShuffleDependency自身:注意是他尾巴上的那个Shuffle,含义一个重要变量ShuffleID
- ShuffleDependency里面的指向的上游RDD。有了它,新生成的Stage就含有上一个窄依赖运算所有的信息,
- 重复第二步,直到没有父节点
Task与Stage:
- task是实际执行的最小单元
- 每一个Stage依据他包含的RDD(由上面知道,就是每个窄依赖的最后一个RDD)的n个分区数目,生成n个task,。主要包含两类task:
- finalStage的task:ResultTask
- 其他所有Stage的task(也可以叫ShuffleMapStage):ShuffleMapTask
- schedule**按顺序(图的从前往后)**调度每个task:
- 寻找所有父依赖的task都完成的task(在driver中,DAGScheduler)
- 序列化需要运行的Task对象(在driver中):注意Task包含了很多信息:runid,stageid,rdd,partition这个是必须的,尤其是把RDD对象序列化了
- 发送Task到executor中(local中没有看mesos)
- 运行Task中定义的run函数(在executor中):
- ResultTask.run:简单的对finalRdd.iterator的调用生成最终结果,会触发rdd的链式调用(合并)
- ShuffleMapTask.run:
- 也是对rdd.iterator调用-->这个RDD一般是窄依赖的最后一个调用,会触发rdd的链式调用(合并)
- 使用定义的agg函数(shuffle合并逻辑)
- 对上述结果使用partitioner分区--》本地分桶
- 分桶结果,分文件输出,文件路径
SparkEnv.get.shuffleManager.getOutputFile决定,后续可以被读取。
- 发送结果到driver??(local中没有看mesos)
- 接收到return的结果(在driver),如:ShuffleMapTask是一个地址,ResultTask是一个值
- 通知完成(在driver,LocalScheduler):taskEnded
- 等待task完成(在driver中,DAGScheduler)
- 如果是ShuffleMapTask:在stage中记录每个task的输出地址
- 如果是ResultTask:标记完成。
- 继续调度剩下可以满足上述条件的task(在driver中,DAGScheduler)
xxxTask中的rdd.iterator调用会引发rdd的链式调用,注意一个特点,这个链式调用/合并的头一般是一个窄依赖的开始RDD,一般是Shuffle后的一个RDD,如果ShuffledRDD/CoGroupedRDD。他们具有如下特点:
* 他们的compute函数包含了fetcher逻辑,从上游读取数据
* 他们没有parent的RDD,rdd链已经到头了
窄依赖的合并原理:在RDD的compute接口实现中(子类实现)对prev的RDD进行调用,因此形如rdd.map().filter()会先生成MappedRDD,在生成FilteredRDD,在生成这些rdd时的构造参数会传入前一个RDD,即prev。FilteredRDD的compute()的实现类似prev.iterator(split).filter(f)。后期shedule调用时,只要引用并调用最后一个RDD的compute即可合并所有计算过程。
shuffle的原理:参考Task与Stage
Scheduler的同步方法使用wait(waitForEvent函数)与notify(taskEnded函数)
DAG->stage图->转化为n个ShuffleMapTask和m个ResultTask(n=ShuffledDependency的数目,m=最后一个rdd的partition数目)
RDD
建议阅读RDD的源码的头部注释,定义了RDD最关键的几个函数
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel.
Each RDD is characterized by five main properties:
- A list of splits (partitions)
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for HDFS)
All the scheduling and execution in Spark is done based on these methods, allowing each RDD to implement its own way of computing itself.
This class also contains transformation methods available on all RDDs (e.g. map and filter).
In addition, PairRDDFunctions contains extra methods available on RDDs of key-value pairs, and SequenceFileRDDFunctions contains extra methods for saving RDDs to Hadoop SequenceFiles.
创建RDD
- parallelize:ParallelCollection
- splits:分块的数组信息Array[ParallelCollectionSplit],其中ParallelCollectionSplit是Split的子类,代表partition
- compute:返回了某个分区代表的某个数组的iterator
- preferredLocations 无
- dependencies:由于是头部的RDD,所以没有为Nil
- partitioner:无,为None,主要用在pairRDD中,这个不是
- hadoopFile:HadoopRDD、NewHadoopRDD
- hadoop inputformat知识
- java序列化知识,http://bluepopopo.iteye.com/blog/486548
输出RDD-存储数据
- savehadoopfile
学习hadoop-InputFormat/OutputFormat相关知识:https://www.cnblogs.com/noures/archive/2012/07/13/2589767.html
转换rdd
单个RDD间转换
- filter -- FilteredRDD
- map -- MappedRDD
- flatMap -- FlatMappedRDD
- glom -- GlommedRDD
- mapPartitions -- MapPartitionsRDD
- pipe -- PipedRDD
- 其他
- groupBy -- ShuffledRDD:RDD的方法,要先转换成(K,V),然后原理参考groupByKey
- sample -- SampledRDD:采样方法
多个RDD合并
- union -- UnionRDD
- cartesian -- CartesianRDD
转化为PairRDDFunctions
- groupByKey/reduceByKey/partitionBy/combineByKey -- ShuffledRDD:shuffle的逻辑(groupByKey reduceByKey),有数据fetch
- 了解aggregator
- 了解partitioner
- join/cogroup -- CoGroupedRDD:join的逻辑,有数据fetch
- 了解aggregator
- 了解partitioner
转化为OrderedRDDFunctions
- sortByKey -- SortedRDD:使用了partitionByRDD间排序,再加上RDD的内部排序
RDD的action
collect take first toArray
count
reduce fold aggregate
foreach
采样:
takeSample
总结
不涉及shuffle的情况下,mapPartitions是一个最通用的函数
- action(count foreach reduce fold aggregate collect等等)时通过sc.runjob+一个partition的函数来为每个计算一个值+最后汇总这个值
- transform(例如filter map flatMap glom)是通过对分区的计算返回一个新的iterator。
Mesos调度
调度的过程由DAGScheduler调用submitTasks方法触发,流程如下:
MesosScheduler -> SimpleJob -> Task(Mesos) -> ...setData发送序列化的task(Spark)... -> Executor
代码逻辑可以简单总结为:Scheduler管理Job,Job管理Task
MesosScheduler
功能包括
- 实现了DAGScheduler作为spark的调度接口
- 主要是submitTasks函数:生成SimpleJob
- start函数接口,是用来运行一个后台常驻的MesosSchedulerDriver线程
- defaultParallelism:spark.default.parallelism 8(todo:需要真实查询mesos获得当前所有executor一共的cores数据)
- 最重要的是,他实现了
org.apache.mesos.Scheduler这个Mesos的入口- Mesos的资源分配(resourceOffers):
- 判断内存是否满足Executor运行条件:
SPARK_MEM环境变量设定 - 调用SimpleJob的slaveOffer获得实际运行Task && launchTasks
- 判断内存是否满足Executor运行条件:
- 状态通知(statusUpdate):更新Job状态 && 调用SimpleJob的statusUpdate更新Task状态
- 其他常见的回调:registered,error,stop
- Mesos的资源分配(resourceOffers):
- 逻辑上:实现了对n个tasks封装为job的抽象,他只负责管理调度job,job再处理tasks,具体参考SimpleJob。
- 额外的:jar包服务器
Mesos-job的概念
spark在使用mesos运行时有个job的概念,对应的类是SimpleJob,会被MesosScheduler调用。我们知道调度的过程由DAGScheduler调用submitTasks方法触发,一次submitTasks的所有tasks形成一个job(参考MesosScheduler的submitTasks函数)。由于,在DAGSchedule中一次submitTasks就是提交一个Stage的所有未完成的Tasks,因此,在初始情况下,Job可以理解成一个Stage。
SimpleJob:
- 构造SimpleJob
- 构造等待任务队列:allPendingTasks包含所有任务
- 构造按host分类的等待队列:pendingTasksForHost,方便本地化运行
- Job内所有Task的资源请求处理-slaveOffer
- 包含数据本地化是否接收offer
- 判断cpu是否满足Task(内存不在这,判断由ExecutorInfo决定)
- 按照host地址查找可以运行的任务
- 按照delay scheduling算法确定任务
- 生成Task(包含了真正运行的data)并返回给MesosScheduler去启动
- 设置task占用的资源:CPU
- 设置task的ExecutorInfo,用来slaver首次运行Task时启动Executor(具体过程参考Mesos中的启动流程)
- setData-序列化的需要运行的真正的Task。
- 包含数据本地化是否接收offer
- Job内所有Task的状态处理:
- 有task运行成功
- taskEnded通知成功
- finished标记+1 && 判断是否需要jobFinished
- 有task运行失败(包括lost和fail):
- 如果是FetchFailed,参考下面『fetcher错误处理』一节,
- 调用taskEnded通知
- finished标记+1 && 判断是否需要jobFinished
- 直接返回(具体原因见『fetcher错误处理』)
- 重新加入等待任务队列allPendingTasks,效果是:下次slaveOffer时会重新运行他!!
- 控制每个task失败次数不超过MAX_TASK_FAILURES(4)次,否则结束这个job(这里不是异常,只是jobFinished-标记job结束,不再调度。todo:kill所有其他正在运行的task)
- 如果是FetchFailed,参考下面『fetcher错误处理』一节,
- task被kill:The task was killed by the executor.类似上面失败的过程,但是不记录失败次数
- 所有task运行完成(不一定是成功!):就是上面的判断是否调用jobFinished(tasksFinished == numTasks )
- 有task运行成功
- 数据本地化细节:
- 把所有task的preferredLocations组织成 host->List[Task]的形式,方便依据机器的host地址选择任务(即pendingTasksForHost队列)
- delay scheduling算法:原理非常简单,在
LOCALITY_WAIT间隔(curTime-lastPreferredLaunchTime)内使用localOnly调度,超时后再开始调度非本地任务。
- ExecutorInfo的细节(见MesosScheduler的createExecutorInfo方法)
- 设置一下Executor的环境变量:SPARK_MEM,SPARK_CLASSPATH,SPARK_LIBRARY_PATH,SPARK_JAVA_OPTS
- 设置了Executor的整体的memory
- command:启动Executor的脚本:spark根目录下的
spark-executor文件 - 启动脚本的参数:本地Driver系统属性中
spark.开头的配置
思考:这个调度框架如何实现任务失败重新获取资源运行?
spark的容错基于一个基本假设:某个机器失败后,大概率不会把失败的机器又分配过来。具体而言:
任务失败后会重新加入等待任务队列allPendingTasks。下次slaveOffer时会重新运行失败的任务。这里只能说下次提供的新资源大概率不是失败的节点。如果需要优化可以添加一个资源黑名单,offer中由经常失败的slaver直接拒绝。(DAGScheduler,108行代码的todo中也说了)
spark-shell
入口类:SparkILoop
入口方法:process函数
基本原理:
- 启动spark-shell,本质上就是运行
scala spark.repl.Main args...命令- 参数解析args:使用scala的
CommandLine来解析,获得settings
- 参数解析args:使用scala的
- SparkILoop.process
- printWelcome
- createInterpreter:构造了intp变量&&初始化(SparkIMain),他内部包含了compiler解释器(核心),intp.interpret(codeString)来解释运行代码
- 构造in:这个控制台是输入流的抽象,自定义了
SparkJLineReader extends InteractiveReader。提供了spark代码补全等功能。注意他的内部实现使用了JLine库(处理控制台输入的Java类库) - initializeSpark:初始化sparkContext变量
- loop:循环读入数据&&解释执行逻辑
- readOneLine:
in readLine prompt,读入scala >后面的一行数据(一般这里读了第一行) - processLine:调用
command(line),解析代码,分为两类:- uniqueCommand:命令行的特殊命令,典型的如
:paste:cp xxx了,对他们进行单独处理。如paste会循环读数据。 - interpretStartingWith:普通代码,又分为3种情况,这里主要看进入执行逻辑
reallyInterpret- intp.interpret(code):真正解析&&运行代码
- 根据返回结果执行
- 成功(Success):返回结果,继续运行
- 失败(Error):返回false
- 命令不完整(Incomplete):使用in继续读取数据&&递归interpretStartingWith
- uniqueCommand:命令行的特殊命令,典型的如
- 死循环
- readOneLine:
- SparkIMain:是整个shell的语句解析的核心类,入口是interpret方法,如果输入了一行完整的语句,主要做两件事情:
- 每一行完整语句构造Request:requestFromLine
- 使用语法解析器syntaxAnalyzer构造语法树Trees(构造失败返回None,认为Incomplete)
- 返回包含语法树和code的Request对象
new Request(line, trees)。注意:特殊处理了只有一层的tree,如赋值语句。
- 编译Request:
req.compile:内部使用了ReadEvalPrint类构造一些新代码,包括- ObjectSourceCode包裹源代码生成新的源码类(ReadEvalPrint.complie编译-注意新类的命名,package $linexxx包下,xxx为行id),在该包名下有read对象
- ResultObjectSourceCode包裹源代码的结果类(ReadEvalPrint.complie编译-包名同上),在该包名下有eval对象
- 两者的关系自己分析代码
- 运行Request: loadAndRunReq--调用
req.loadAndRun- 调用了上面生成的
eval对象中的export值,来开始执行整个request(代表一行代码)
- 调用了上面生成的
- 返回结果
- 每一行完整语句构造Request:requestFromLine
- 重要技术点
- 在shell中生成的类需要传递给集群中的其他机器,因此我们需要
- 把每一行编译生成的类存储到一个目录中(outputDir),初始化compiler时直接设置就行
- 提供一个服务器classServer(服务器地址通过spark.repl.class.uri环境变量),是得其他机器能访问到生成的类
- 需要一个特别的classloader可以动态读取远程路径加载里面的新增的class--
ExecutorClassLoader
- 在shell中生成的类需要传递给集群中的其他机器,因此我们需要
accumulator
broadcast
几个重要的问题
shuffle fetcher错误处理(分布式):
- 流程
- submitTasks任务后,会序列化任务发送给Exectuor执行task。由于task包含了stage合并后的逻辑,所以一般都会有fetch逻辑
- SimpleShuffleFetcher:
- 根据某个shufflerID(注意他是上游的shuffleID)获取某个reduce的上游数据数据,一个分块重试4次,失败后抛出异常--包含了上游的shuffleID(Executor中)。注意:这里隐含了必须要重新执行上游的任务,否则只重启自身是没有用的。
- Eexcutor捕获异常,序列化后把FetchFailed异常通过mesos的sendStatusUpdate方法发送给Scheduler(master)
- MesosScheduler的statusUpdate获得task的异常状态,调用该task所属的SimpleJob的statusUpdate方法来处理,该方法会
- 反序列化异常,并调用taskEnd,通知DAGScheduler的逻辑
- DAGScheduler:
- 获得了异常,以及异常包含的上游的shuffleID
- 使用上游的shuffleID找到上游Stage(注意ShuffleMapStage的结构)
- 移除上游完成的标记removeOutputLoc
- 把改stage加入失败队列,等一段时间后重新提交该上游Stage的所有Task(todo:先kill上游Stage没有完成的task)
- DAGScheduler中只要
- 收到FetchFailed失败会无限次重试!!!
- 收到其他Exception一律退出跳出程序
- 结论:
- 下游的某个task由于fetch导致失败,但是其他task成功并不会重算其他task,只会重算该task。
- 虽然下游只有一个task失败(甚至就是fetch某一个分块重试四次失败)会导致整个上游stage的所有task重算(因为shuffle)
- stage重算可以无限循环
spark.default.parallelism
表示程序的并行度,
设置由Scheduler决定:
- localScheduler:线程数目
- MesosScheduler:当前为8(spark.default.parallelism配置)
影响范围:
- 影响了使用Partitioner的方法(作为参数),主要是shuffle操作可能有包括groupBy,join。可以理解为含有过个分区的的reduce操作
- 影响了一些读入数据
- parallelize、makeRDD 直接指定并行度
- textFile,hadoopFile,SequenceFile的最小并行度,如果文件分块比这个值小,则运行时使用parallelism
不影响 :
- map,filter等没有shuffle的操作:并行度与之前的RDD一直
- spark读入hdfs的文件:与文件存储的分片有关(大部分情况下)
资源问题
mesos集群的Executor的资源由两部分组成:
- 内存:对每个Executor是固定的(SPARK_MEM决定),具体而言在mesos框架的ExecutorInfo中指定死了。
- cpu:由当前Executor实际运行Task的个数动态决定,每个Task占1个cpu(由spark.task.cpus配置),即spark.task.cpus * n。由于mesos框架的性质:新加入Task,cpu资源自动加入。同样,Task运行完成,每个task的cpu资源会自动释放。
preferredLocations问题
这里讨论一下spark中选择任务执行位置时的策略,我们知道选择发生在Scheduler中,具体而言,对于Mesos来说发送在MesosScheduler对资源offer的选择时,从上面的分析可以知道,就近调度的策略只使用了一个关键数据来判断位置,就是Task中的preferredLocations函数,该函数中只是简单的返回了参数传入的位置locs,这个值是在DAGSchedule中决定的。
我们知道一个Task,无论是ResultTask还是ShuffleMapTask都包含了某个Stage中N个RDD的逻辑(或者说一个窄依赖内PipeLine形成的逻辑,在Stage中可以由最后一个RDD表示),因此,这个Task的preferredLocations值是由这N个RDD共同决定的。决策关键代码在DAGSchedule中getPreferredLocs,他的输入是finalRDD或者Stage的最后一个RDDstage.rdd。会把Stage内的RDD从后到前寻找满足如下条件的Location:
- RDD是否存在于Cache中,如果在返回Cache位置
- 调用rdd.preferredLocations获取期望运行的位置,有则返回。(具体情况看下面)
- 对rdd的每一个窄依赖(NarrowDependency)的rdd向上递归上面步骤,返回第一个找到的位置。
RDD的preferredLocations函数根据当前的分片返回期望调度(preferred)的位置列表。随着我们不断的运行算子,一个RDD不断的Transform为新的RDD,此时也会发生改变。RDD的分类和preferredLocationsd的实现情况如下:
- RDD生成:
- ParallelCollection(parallelize生成):无
- HadoopRDD/NewHadoop(RDD文件输入textFile、sequenceFile等):返回文件的locations,与hdfs上文件分布一致,参考下面『如何结合hdfs的多副本就近访问』
- 无shuffle依赖的RDD:
- MappedRDD/FilteredRDD/FlatMappedRDD/GlommedRDD/MapPartitionsRDD(对应map,filter,flatmap,glom,mapPartitions):无
- PipedRDD:无
- UnionRDD:转换为上游某个RDD的Split的preferredLocations
- CartesianRDD:合并两个RDD的preferredLocations数组。运行时由于必须要传递一部分数据,失去了部分数据本地行
- SampledRDD:使用pre那个RDD的preferredLocations。如果原理和我下面理解的一样,使用Nil也可以。
- 含Shuffle依赖的RDD
- ShuffledRDD:Nil(等价无)
- CoGroupedRDD:Nil(等价无)
- SortedRDD:无
Shuffle相关的任务直接preferredLocations赋值为Null,强调会失去了本地运行
总结可以发现:
- 使用Cache可以打断寻找preferredLocations的流程,直接优先使用Cache
- 只有窄依赖存在preferredLocations,任何宽依赖(含shuffle)都会失去信息
- 我们发现很多含有窄依赖的RDD(MappedRDD),preferredLocations没有实现。很好理解,根据DAGSchedule中的代码会向上递归查找窄依赖的rdd,所以使用默认的实现返回Nil无伤大雅。除非有些RDD的preferredLocations需要特殊处理时,才要实现改逻辑,来停止递归逻辑,如UnionRDD等。
- 由上面可知
- ShuffledRDD,SortedRDD:如groupBy必然会触发shuffle,preferredLocations就会消失
- CoGroupedRDD:看情况,可能出现上游窄依赖的情况,以join操作为例
- 目标partitioner与某一个RDD的partitioner相同,此时会使用这个RDD的preferredLocations
- 目标partitioner与两个RDD的partitioner相同,此时会使用第一个RDD的preferredLocations
- 目标partitioner与两个RDD均不同(最常见,因为join默认的partitioner是HashPartitioner,大部分RDD默认是None):preferredLocations就会消失
如何结合hdfs的多副本就近访问?
在Spark中参考HadoopRDD、NewHadoopRDD类,都是用了hdfs的API来操作,由几个关键点如下
- inputformat是hdfs数据读取的入口,他包含了所有的信息
- 可以获得InputSplits,这个包含了一个重要信息Location数组(因为多副本存储)。表示InputFormat期望这个Split被处理的Location,理想的情况下,这个api会返回多个副本的Block的真实位置,或者就近的位置。(但是,它完全可以跟实际Block的Location没有半点关系)
- 可以获得RecordReader,他可以实际读记录。会根据InputSplits实现(如FileSplit)中的具体文件的Path信息(注意:不是Location!,而只是一个hdfs的路径)和offset信息读取真实的数据。
- 为了获得数据本地性,我们只要把preferredLocations设置为HDFS的InputSplits的Locations即可!!其原理是:如果我们从Location的机器上运行RecordReader去读HDFS数据,那么首先Path会传递给NameNode,他会根据我们机器的位置和Path的位置,给我们返回一个就近Block副本的机器,此时本地的RecordReader就能就近访问了。
- 由于InputSplits的Locations是多个位置,我们把它作为preferredLocations的函数返回值,就会实现了容错的本地性。其原理和之前『如何实现任务失败重新获取资源运行?』一致,某个副本错误后,大概率不会把失败的机器又分配过来。新分配的资源同样会查找preferredLocations位置,优先运行。
Split是逻辑概念,Block才是HDFS真实的位置
参考这篇文章讲解了HDFS文件读取的本地化机制。
可能的优化点
- shuffle 的纯内存,容易爆了
- Scheduler剔除经常出错的节点
- 资源控制:如何控制executor的个数,也没有控制每个executor的最大cpu数目(容易把集群的所有cpu都占了)