发布模式
gitk --simplify-by-decoration --all
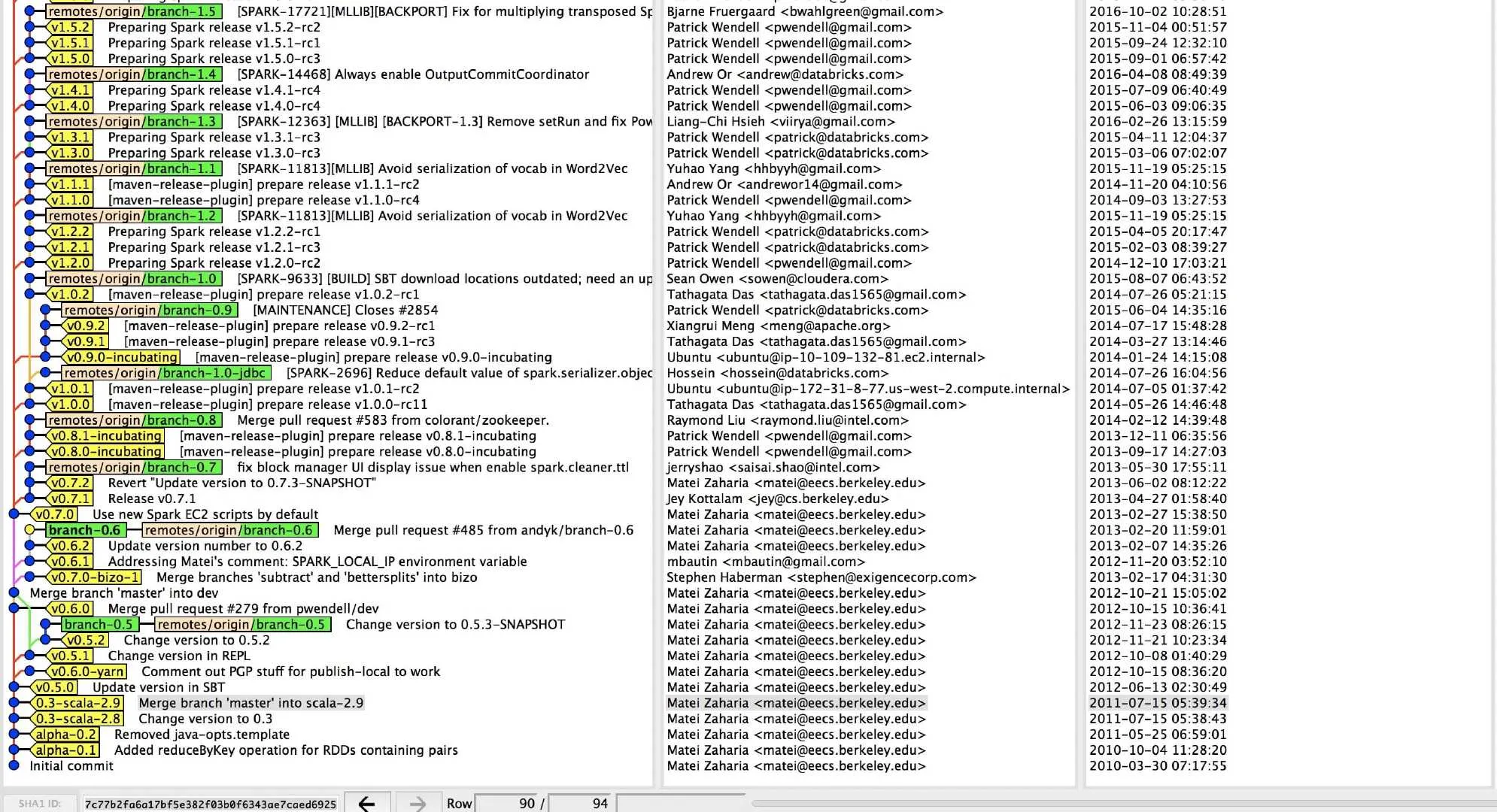
猜测:
- v0.7.0之前,发布模式是在发布当前主版本(如v0.5.0)时,
- 继续用当前分支作为主版本的子版本开发(v0.5.1),对0.5.0的版本进行bug处理(master发布)
- 拉出下个版本的dev分支,同时继续下一个主版本的dev分支,并开发v0.6.0版本(dev发布)
- 特点是:master和dev分支都发布版本不受限制,甚至基于master又拉了其他分支也可以发布版本。
- v0.7.0之后,统一用master分支开发(红色的线),只用其他分支来发布版本。要发布版本是拉个新分支,然后改bug在master上,需要更新到某个版本时backport过来(应该用的是cherry-pick)
各个版本特性
https://spark.apache.org/releases/
https://spark.apache.org/news/index.html
0.5.x
- mesos支持
- 新操作
- sortByKey
- takeSample
- 性能优化
- join的相同partitioner处理
- 可配置的serializer
- Scala 2.9.2
- 通用的Accumulators接口,支持自定义
0.6.x
- standalone的部署模式(包括webui),实验性的yarn模式
- java API(略)
- 性能提升2x
- 架构修改
- custom storage and communication layers (来自即将发布的[spark streaming] (https://people.csail.mit.edu/matei/papers/2012/hotcloud_spark_streaming.pdf))
- communication manager:asynchronous Java NIO
- storage manager: storage level settings
- scheduler优化:better support ultra-low-latency jobs (under 500ms) and high-throughput scheduling decisions
- api的变换
- persisit可以控制缓存策略:内存,磁盘,序列化的bytes
- SparkContext.addFile/Jar动态添加jar包
- join支持设置partitioner
0.7.x
- 一个大版本
- python API
- spark streaming 测试版-- http://www.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-259.pdf
- 一个web ui:内存监控Dashboard
- 支持maven build
- transformations:keys, values, keyBy, subtract, coalesce, zip
- SparkContext.hadoopConfiguration可以全局配置hadoop input/output settings
- RDD.toDebugString()
- 其他提升
- shuffule并行度,除非设置spark.default.parallelism,否则用 自动推断
- Standalone提升:默认 spreads jobs out,web UI 添加了json,分离相关配置
- sheduler重构。。支持更好单元测试
- New API methods: subtractByKey, foldByKey, mapWith, filterWith, foreachPartition, and others.
- SparkListener interface, 可以收集各种性能指标metrics,如每个stage的task lengths, bytes shuffled
- standalone支持在一个机器上启动多个worker实例
- spark-shell支持添加jar,通过ADD_JARS变量
0.8.x
这个版本开始有了databricks的博客,可以参考这个学习
-
dashboard扩展成了webUI,和现在的差不多了
-
MLlib库(基于MLBase):支持的算法
- SVMs
- logistic regression
- several regularized variants of linear regression
- a clustering algorithm (KMeans)
- alternating least squares collaborative filtering.
-
继续提升python API,支持了notebook的ipyhton
-
hadoop yarn的正式支持
-
schedule的重构升级:支持更多调度策略,支持多用户共享Spark实例,机架感知,单机多Executor
-
剥离了hadoop-core的jar依赖,而是依赖hadoop-client,可以使用用户自己的任意hadoop版本??参考这里
-
其他升级
- 支持unpersist
- RDD新api:takeOrdered, zipPartitions, top
- JobLogger类,
- RDD.coalesce 升级
- RDD.pipe 支持传递环境变量
- hadoop save 支持compression codec.
- 可以把spark打包成一个仅依赖java的二进制包,方便部署???
- 增加了example
- mesos升级,可以把spark打包成一个mesos jar,直接部署,不需要预安装。
-
包名变了org.apache.spark
-
If you are building Spark, you’ll now need to run sbt/sbt assembly instead of package.
-
升级了yarn2.2的支持
-
Standalone的高可用--master的高可用(使用zk实现),让长期运行spark成为可能(如spark streaming)
-
性能优化
- shuffle的hashtables优化:减少内存和cpu消耗
- JobConf支持高效的encoding,提升了spark从hdfs读取大块数据的效率
- Shuffle 文件合并(默认关闭,0.9会打开)--减少shuffle文件输出个数
- Torrent广播(默认关闭)-- 大对象的快速广播
- 支持获取大的result集合,而不需要调整akka的buffer
-
新api
- repartition操作
- Spark Streaming operators: transformWith, leftInnerJoin, rightOuterJoin
-
ui中添加了result fetching状态???
-
standalone / Mesos 模式支持以不同用户的身份运行spark??
-
bug:修复了在某些任务失败后挂起调度程序???
0.9.x
- Scala 2.10
- SparkConf类来配置SparkContext(推荐)
- spark streaming正式版,
- 简化了高可用的设置(standalone)
- window操作提速30-50%
- input source plugins (e.g. for Twitter, Kafka and Flume) are now separate Maven modules
- StreamingListener interface
- 大量api
- StreamingContext.awaitTermination() 允许等待运行结束,捕获异常
- GraphX的测试版,目的取代Bagel API.
- 从rdd构建图
- 从图中抽取任意子图
- Pregel API
- 标准算法,如pagerank
- Interactive use from the Spark shell
- mllib库提升,支持python
- spark的脚本放到了bin(spark-shell)、sbin(管理脚本,start/stop standalone)目录中
- core升级
- spark standalone支持在集群内提交(以前是在集群外提交)
- reduce会spill数据到磁盘上了!!(以前是存内存,容易oom)
- standalone支持设置使用的cpu cores(以前是使用所有能用的核)
- spark-shell支持
-i选项来指定移动运行的脚本 - 统计类api: histogram/countDistinctApprox
- yarn模式升级,支持了发送外部文件,修复bug
- bug修复,可以看issue tracker,参考release-note 0.9.1-bug列表,0.9.2-bug列表
- spark-core bug修复
- yarn的bug修复
- 更方便的整合Tachyon--一个内存框架!!
- ml优化
- pyspark bug,增加操作
issue tracker使用:地址
1.0.x
-
yarn安全模式整合??
-
运营优化
- spark-submit脚本,统一提交任务的入口
- history-server
-
Spark SQL 测试版:提供了对结构化数据的处理
- 支持加载外部的结构化数据,如Hive和Parquet。
- 支持给RDD添加Schema
- spark sql与RDD交互:实现了sql语句与spark代码的转换
- 使用 Catalyst优化器形成高效的执行图,自动对parquet格式进行谓词下堆优化
- 未来版本中,spark sql会对其他存储提供一个通用的API
-
mllib
- 增加对稀疏特征向量的支持,可以提速 linear methods, k-means, and naive Bayes.
- 新算法:SVD / PCA
- 模型评估函数
- L-BFGS?
-
graphx
- 性能提升
-
spark streaming
- 状态转换的性能优化
- Flume的支持(日志收集系统,之前支持kafka,twitter)
- 长期运行任务的自动状态清理
-
java8的支持:lambda表达式
-
其他小升级
- instrumentation支持,运行对任务监控
- 添加Tachyon对堆外off-head内存整合的支持,通过一个build target实现的
- cache添加DISK_ONLY的支持,对大数据集可能有用
- 当RDD没有引用时,spark job创建的中间状态会自动垃圾回收了??
- SparkContext.wholeTextFiles方法,可以把小文件看做一个recored来操作
-
bugfix--tracker1.0.1 tracker1.0.2
- 重大bug参考release-note1.0.1, release-note1.0.2
-
spark sql新特性
- json数据读取
- parquet提升:支持嵌套record,和array
- 支持一些新sql语句: (CACHE TABLE, DESCRIBE, SHOW TABLES)
- 支持sql相关的配置:设置partition数目
1.1.x
这个版本的spark增强了磁盘(非内存)的排序的速率(并在100tb的比赛中击败了hadoop,2014年11月),涉及几个重要的pr参考:
- https://databricks.com/blog/2014/10/10/spark-petabyte-sort.html
- https://databricks.com/blog/2015/04/24/recent-performance-improvements-in-apache-spark-sql-python-dataframes-and-more.html
- spark-core性能提升
- 可用性提升,对长期运行的复杂任务的性能监控的提升
- accumulate在ui中显示名称
- 动态更新task的进度条
- 对输入数据的文件系统相关指标的监控
- spark sql新特性
- thift jdbc/odbc服务器,运行用户共享使用cache的数据,参考
- 加载json数据为schemaRDD格式,自动schema推断。
- 使用动态字节码技术codegen优化spark sql中表达式计算时间,原理解释:是否scala反射解析代码
- 支持自定义udf(spark sql中才需要udf,rdd中都是自己写函数),并且可以在sql中直接调用
StructField/structType从自定义数据源读取数据生成schemaRDD- 对原生parquet的很多优化
- mllib
- 新算法:通用的统计函数,特征抽取工具(Word2Vec/ TF-IDF) 非负矩阵分解
- 性能提升
- spark streaming
- 流式机器学习算法,流式线性回归
- 对inputs的速率限制rate limiting
- GraphX
- 自定义顶点和边的storage level
- 提高数值精度
- issue解决
- Spark Core: http://s.apache.org/spark-1.1-core
- Spark SQL: http://s.apache.org/spark-1.1-sql
- Spark Streaming: http://s.apache.org/spark-1.1-streaming
- MLlib: http://s.apache.org/spark-1.1-mllib
- PySpark: http://s.apache.org/spark-1.1-pyspark
- All issues: http://s.apache.org/spark-1.1-all
- spark-1.1.1-release
1.2.x
-
scala2.11
-
spark-core性能优化
-
spark-streaming
- python api
- 引入WAL实现HA(optional),把日志写入HDFS,参考
-
mllib
- 支持learning pipelines??
- 与spark sql兼容,使用SchemaRDD表示数据集
- 决策树算法加入了随机森林和GBDT
-
spark sql
- 新的api读取外部数据源
- 支持读入数据注册成为一个临时表,来支持谓词下堆的优化
- json parquet的绑定API重写??
- hive提升。。。看不懂
- 优化了缓存SchemaRDD的架构性能,支持基于统计的分区修剪。
-
graphX
- 作为正式版发布
- aggregateMessages API的引入:更更大的编程模型和更好性能(1x提升)
- graph支持了checkpointing和lineage truncation(对于大量迭代有优化)
-
bug-fix
- 1.2.1 issue tracker, release-note
- 1.2.2 issue tracker,release-note
- Netty shuffle 线程安全
- JobProgressListener内存泄漏
1.3.x
-
spark-core
- 加入 treeAggregate treeReduce这两个api(对aggregate的升级)
- jetty依赖改成了内置的shade方式(直接打包到内部了)
- 某些连接支持ssl(如内存的控制信号的通讯&&httpserver)
- ui界面上加上了垃圾回收时间&&record数目
-
DataFrame API的加入
- SchemaRDD已经废弃,改为DataFrame
- 目的是记录有schema的RDD数据,统一表示结构化数据,如hive json jdbc等等
- 可以作为不同数据源转换的中间数据结构
-
spark sql 正式版发布
- 支持data source api 的table的写操作
- 新的jdbc data source支持mysql/Postgres等数据库的导入导出
- 支持parquet的merge schema
-
mlLib
- lda主题建模
- 多分类的逻辑回归
- 聚类算法:高斯混合模型GMM | power iteration clustering
- FP-growth
- 分布式线性代数工具:块矩阵的抽象
- 模型的导入导出
-
spark streaming
- direct Kafka API (支持不需要WAL的exactly once)
- 在线逻辑回归算法
- 支持读取二进制recored
- stateful operations: loading of an initial state RDD
-
graphx: canonical edge graph.
-
bug-fix
- 1.3.1 issue tracker,release-note
- Thread safety issue in Netty shuffle
- Memory leak in output committer map
- 1.3.1 issue tracker,release-note
1.4.x
从1.4这个版本开始引入了一个重要的优化项目Tungsten(1.5也有),关于Tungsten的优化列表参考,1.4主要是:
- 显式的对内存进行高效的管理(针对df的agg函数)-codegen
- 自定义的序列化器(jira中觉得Kryo还是慢)
- sparkR引入
- spark-core 性能优化
- ui支持显示dag图的可视化
- shuffle
- 减少排序时的内存占用,sort-base的shuffle在内存中会有很多小的object,如果以serialized的形式存储更节省空间。参考
- 一个测试的shuffle manager--tungsten-sort
- mesos的docker支持
- spark-sql/DataFrame优化,完整参考
- ORCFile的支持
- 对大的join操作支持Sort-merge
- thift server加了一个ui的监控界面
- DataFrame加入一下数学函数,支持列计算
- DataFrame加入窗口函数
- DataFrame的join API支持self join,就是两个表相同的列自动join??
- data source api支持分区读写(分区目录存储数据)
- 支持rollup cube 函数(有点类似groupBy,但是又有区别)
- DataFrame支持describe,显示一些基本的统计值,如mean std等
- mllib,参考release-note
- ML pipelines支持更多的tramsform
- spark streaming
- ui支持
- 对kafka的input rate 的跟踪
- 可插拔的WAL接口
- bug-fix
- 1.4.1 issue-tracker realease-note
1.5.x
这个版本继续优化项目Tungsten,包括:
- expanded binary memory management:更多的操作支持内存管理-codegen
- cache-aware data structures:设计算法和数据结构以充分利用memory hierarchy
细节变化参考
-
RDD/DataFrame/SQL的api变换
- UDAF(experimental)
- DataFrame支持设置broadcast Join:broadcast函数
- expr函数:支持sql表达转换成DataFrame column
- 更新NaN的支持
- NaN functions: isnan, nanvl
- dropna/fillna also fill/drop NaN values in addition to NULL values
- Equality test on NaN = NaN returns true
- NaN is greater than all other values
- In aggregation, NaN values go into one group
- SPARK-8159: Added ~100 functions, including date/time, string, math.
- 一些新的数据类型
- CalendarIntervalType
- TimestampType
- checkpoint优化,参考
-
DataFrame/SQL的底层优化
- codegen默认打开了
- agg聚合函数优化
- Cache friendly in-memory hash map layout
- 内存超的时候退回到外部排序的聚合
- agg也会codegen了
- join的优化
- 在有shuffle的join操作中,更倾向于使用基于外存的sort-merge算法,使得join只受磁盘大小的限制(而不是内存大小)
- 支持sort-merge的left/right outer joins
- 支持broadcast outer join
- sort的优化
- Cache-friendly in-memory layout for sorting
- 内存超的时候退回到外部排序的聚合
- comparator也使用了codegen技术
- Native memory management & representation
- 更紧凑的内存数据表示,占用内存更低
- 优化了运行时内存,减少JVM GC的影响,更少的GC,更健壮的内存管理
- window函数的性能和内存优化,https://issues.apache.org/jira/browse/SPARK-8638
- 执行计划可视化&&内存metric
-
外部整合
- mesos:
- SPARK-6287: mesos中实现动态资源管理的粗粒度模式
- SPARK-6707: 用户自定义slave的属性
- YARN
- SPARK-4352: **实现了基于位置的动态Yarn作业分配&&
- standalone
- SPARK-4751: 动态资源管理
- 更好的hive metatore支持
- 支持json数据源数据分区?
- parquet
- 优化速率,schema发现和合并
- 默认开始谓词下堆
- mesos:
-
mllib
- 更多transform: CountVectorizer, Discrete Cosine transformation, MinMaxScaler, NGram, PCA, RFormula, StopWordsRemover, and VectorSlicer.
- 更多Estimators: SPARK-8600 naive Bayes, SPARK-7879 k-means, and SPARK-8671 isotonic regression.
New Algorithms: SPARK-9471 multilayer perceptron classifier, SPARK-6487 PrefixSpan for sequential pattern mining, SPARK-8559 association rule generation, SPARK-8598 1-sample Kolmogorov-Smirnov test, etc. - 性能提升
-
spark-streaming
- 背压算法:动态控制输入数据流,支持kafka SPARK-7398
- kafka Direct Kafka API正式发布
- ui中加入更多输入信息,如kafka offset
- recevier更好的调度和负载均衡SPARK-8882:
-
手动内存管理Tungsten默认开启
-
bugfix
1.6
spark-core/spark sql
- api变换
- Dataset API
- Session Management:SparkSession?不同用户共享集群,可以配置不同的配置文件,设置不同的tmp表
- Cache数据的高层分布信息:在扫描内存表时,存储了分区和order的schema信息 且DataFrame添加了distributeBy / localSort API
- 支持文件上直接运行sql,不需要先注册成为table
- 支持sql的*操作选择schema??(用structType定义的?)
- json读入功能增强,支持非标准的json,支持设置把数据都读成string
- ui中可以显示每个操作的性能指标
- 性能提升
- 联合内存管理:合并了执行内存和cache所用的内存,现在他们共享内存,统一管理。
- 提升内存中列式数据缓存的性能:如DataFrame的数据缓存,如果内部含复杂的数据类型,性能提升14x
- Off-Heap内存:堆外内存支持
- 自适应的查询执行:支持自动配置join/agg的reduce的个数
- 更快的 null-safe joins:这中join 参考,这里优化了速率,之前是使用笛卡儿积来做的,现在使用sortmerge
- Parquet性能提升
spark-streaming
- 新的状态管理mapWithState,希望取代updateStateByKey
mllib
- 新算法、模型
- Online hypothesis testing - A/B testing in the Spark Streaming framework
- New feature transformers - ChiSqSelector, QuantileDiscretizer, SQL transformer
- api提升
- ml-pipeline:支持pipeline持久化,lda
bug-fix
2.0.x
spark-core/spark-sql
- api
- DataFrame与Dataset 统一了
- 引入SparkSession,代替SQLContext HiveContext
- 新的accumulator api,改进之前的设计,更加简单易用
- 新的Aggregator API,用于Datasets中的 typed aggregation
- spark sql
- 支持SQL2003标准,可以运行TPC-DS测试基准的所有99个查询
- 一个原生的SQL解释器,支持ANSI-SQL与Hive QL(即原始SQL与HQL)
- 原生的DDL实现(表修改操作),之前推荐使用HiveContext metastore。catalog API。当前默认metastore是in-memory参考
- 支持子查询subquery(嵌套sql)
- View canonicalization???
- 新特性
- 原生的csv文件的读取
- 用Off-heap内存管理运行时和cache内存
- 使用sketches库实现了近似统计算法,sketches library:包括approximate quantile, Bloom filter, count-min sketch等算法
- Hive 表存储支持 bucketing方式,
bucketBy
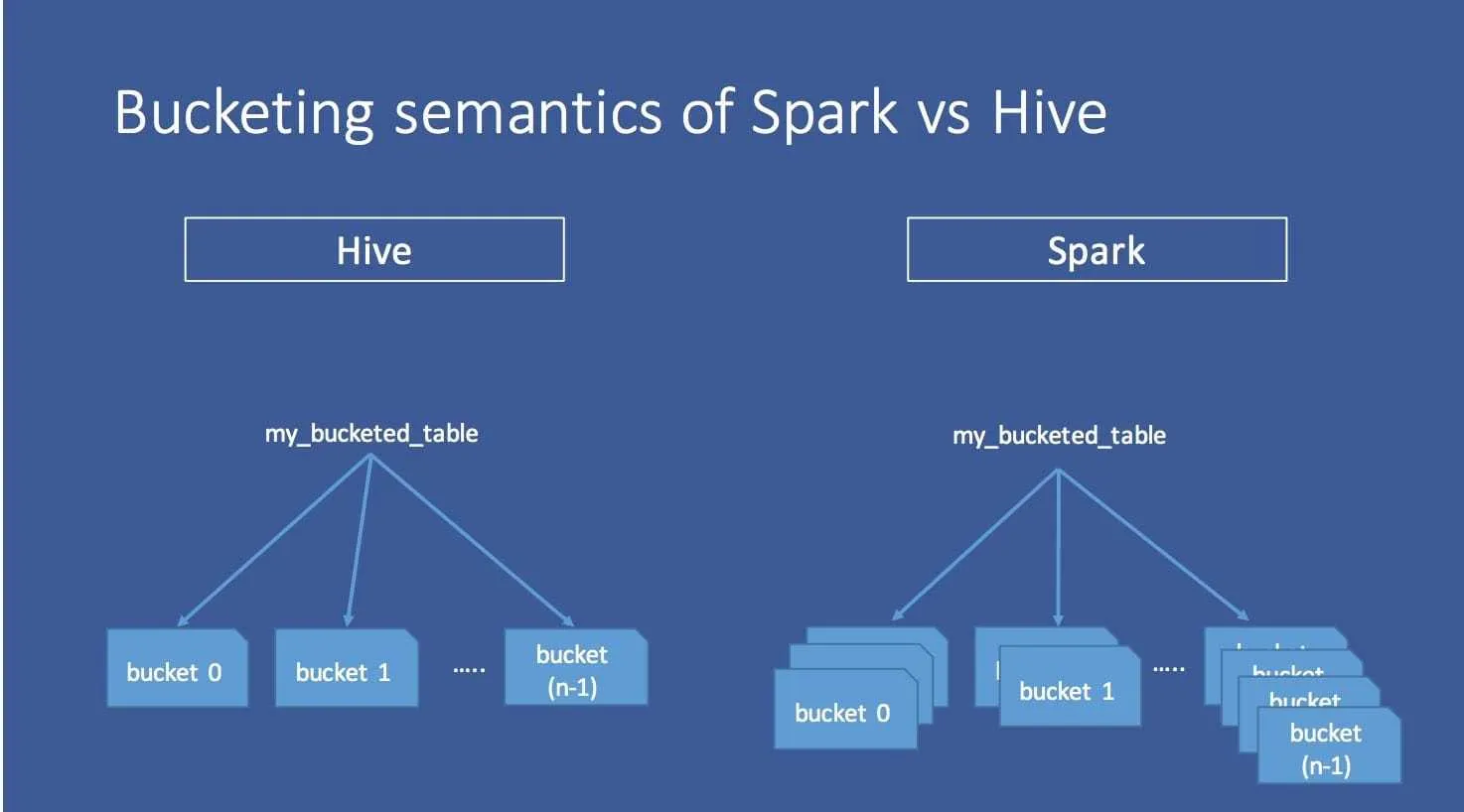
- 性能
- spark-sql支持了whole stage code generation
- 通过vectorization提升parquet扫描性能
- Catalyst查询优化负载优化
- sql的窗口函数优化(通过原生实现这些函数)
- 本机数据源的自动文件合并(coalescing)
MLlib
- 使用DataFrame作为主要API,RDD作为维护
- 性能:优化了DataFrame中Vectors和Matrices的性能
spark streaming
- Structured Streaming实验版,使用了Catalyst优化
sparkR
支持udf
其他
- no longer requires a fat assembly jar for production deployment.
- 异常akka的依赖,user applications can program against any versions of Akka.(为了解决某些用户已经用了Akka的冲突)
- coarse grained Mesos mode中可以启动多个executors
- 使用Scala 2.11构建
- Mesos Fine-grained mode 会在以后2.x中移除
issue
Catalog和自定义Optimizer
https://bigdata-ny.github.io/2016/08/21/spark-two-series-part-2/
2.1.x
- spark streaming
- Structured Streaming加入event time watermarks(在其他api里面没有watermark) SPARK-18124
- Structured Streaming加入kafka 0.10支持 SPARK-17346
- 支持长时间稳定运行SPARK-17267
- spark-core/spark-sql
- api
- 加入
from_json,to_json函数可以用在col上了 - 修改
DataType的api为稳定的(从1.3开始之前是develop状态),他的子类如BinaryType/BinaryType/StringType
- 加入
- 性能
- metastore中加入存储了分区信息。没有分区信息的化spark会读取所有分区到内存,查看schema,加入分析信息后只需要加载需要访问的分区的schema就行,提高首次加载速度(如果表很多分区的化)https://issues.apache.org/jira/browse/SPARK-16980
- 提升groupby agg的性能,通过加入聚合cache实现 SPARK-16523
- api
- MLLib
- 局部敏感Hash
- 多类别的逻辑回归的DataFrame API
- bugfix
2.2.x
- api
- Catalog扩展
- Support creating hive table with DataFrameWriter and Catalog
- 添加外部修改catalog的事件监听
- 支持了
LATERAL VIEW OUTER explode()语法 - 对sql增加了BROADCAST, BROADCASTJOIN, and MAPJOIN
- 支持sql修改表名: ALTER TABLE table_name ADD COLUMNS
- df加入了
hint函数,支持设置broadcast等操作 https://issues.apache.org/jira/browse/SPARK-20576
- Catalog扩展
- 性能优化
- sql
- Cost-Based Optimizer(基于代价的优化技术) :。。。略
- agg操作的性能优化:使用了JVM object
- core
- kill不了的进程不要饿死其他job:SPARK-18761
- cache增加拓扑感知功能:如果某个机器挂了,就不用在选择他缓存block了(之前似随机选择的)SPARK-15352
- 调度增加黑名单机制:SPARK-8425
- sql
- 其他,支持多行json/cvs的解析
- Structured streaming 正式版发布
- SPARK-19067: Support for complex stateful processing and timeouts using [flat]MapGroupsWithState
- SPARK-19876: Support for one time triggers
- MLlib
- 加入新算法LinearSVC ChiSquare Correlation
- bug-fix
2.3.x
Core, PySpark and Spark SQL
- 新特性
- Spark on Kubernetes
- Spark History Server V2
- Data source API V2 (实验)
- Vectorized ORC Reader
- core
- SPARK-21113:spill reader读buffer优化--read ahead
- SPARK-22062 17788 21907:各种oom错误
- SPARK-19112:ZStandard codec支持
- sql
- cost-based optimizer
- Histogram 支持
- rule-based optimizer增强
- codegen 64k jvm限制
- SPARK-23207:一个长期存在的bug
- SPARK-20746:更多udf支持( ISO/ANSI 标准)
- cost-based optimizer
Structured Streaming
- Continuous Processing(experimental):支持毫秒级的数据处理(at-least-once)
- Stream-Stream Joins:支持两个stream的join操作
- Streaming API V2(experimental)
mllib
这个版本ml变化挺多,看releasenote
- 支持 Structured Streaming
- 支持读取图像数据
- LogisticRegression的api大幅的变换了
bug-fix
总结:
spark2.x很少包含spark-core的大优化了,大部分是spark-sql